
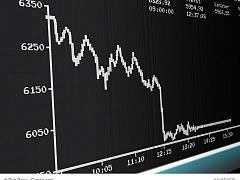
Sistrix zeigt deutlich niedrigere Sichtbarkeit für viele Websites
Der Sichtbarkeitswert von Sistrix für viele Websites ist gestern deutlich gesunken. Inzwischen haben sich die Werte ein wenig erholt.

Bei den Zugriffen der Crawler auf Web-Inhalte hat es deutliche Veränderungen gegeben. Google liegt noch immer deutlich vorne, aber der GPTBot legte enorm zu.

Web-Crawler, sind seit jeher das Rückgrat des Internets, weil sie Inhalte für Suchmaschinen indizieren, um Nutzern relevante Ergebnisse zu liefern. In den letzten Jahren hat sich ihre Rolle jedoch grundlegend gewandelt: Mit dem Aufkommen der künstlichen Intelligenz ist eine neue Kategorie von KI-Crawlern entstanden, die nicht nur für Suchmaschinen, sondern auch zum Training von KI-Modellen Daten sammeln. Diese Entwicklung wirft neue Fragen bezüglich Urheberrechten, unerlaubter Datennutzung und der Belastung der Infrastruktur auf. Insgesamt machen Bots, zu denen sowohl harmlose als auch bösartige Crawler gehören, heute bereits etwa 30 Prozent des weltweiten Internetverkehrs aus, wie es im Blogbeitrag von Cloudflare heißt.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



Die Analyse der Crawler-Aktivitäten von Mai 2024 bis Mai 2025 zeigt ein deutliches Wachstum: Der gesamte Traffic von KI- und Such-Crawlern stieg in diesem Zeitraum um 18 Prozent. Berücksichtigt man Neukunden, die in dieser Zeit hinzugekommen sind, beläuft sich der Anstieg sogar auf 48 Prozent. Der Höhepunkt des Crawler-Verkehrs wurde im April 2025 verzeichnet, mit einer Steigerung von 32 Prozent gegenüber Mai 2024. Diese Zahlen bestätigen einen klaren Aufwärtstrend im Web-Crawling.
Die Verteilung der Top-Crawler hat sich im letzten Jahr erheblich verändert, was die zunehmende Integration von KI in Suchmaschinen und darüber hinaus widerspiegelt.
Der Googlebot, der für die Indexierung von Inhalten für die Google-Suche zuständig ist, blieb der unangefochtene Spitzenreiter und baute seine Vormachtstellung sogar noch aus. Sein Anteil am gesamten Crawler-Traffic stieg von 30 Prozent im Mai 2024 auf 50 Prozent im Mai 2025. Dies entspricht einem Anstieg der Roh-Anfragen um 96 Prozent. Dieser Zuwachs könnte auch mit den neuen KI-Features wie den AI Overviews und dem Google AI Mode zu tun haben. Ein weiterer Google-Crawler, GoogleOther, der 2023 für Forschungs- und Entwicklungszwecke eingeführt wurde, verzeichnete ein Wachstum von 14 Prozent bei den Anfragen.
Eine der auffälligsten Veränderungen ist der rasante Aufstieg von Crawlern, die speziell für KI-Zwecke konzipiert sind. Der GPTBot wird zur Verbesserung und zum Training von großen Sprachmodellen von OpenAI eingesetzt. Sein Anteil am gesamten Crawler-Traffic stieg von lediglich 2,2 Prozent im Mai 2024 auf 7,7 Prozent im Mai 2025, was einem Anstieg der Anfragen um 305 Prozent entspricht. Damit kletterte der GPTBot von Platz 9 auf Platz 3 der meistgenutzten Crawler. Im Bereich der reinen KI-Crawler stieg der GPTBot von 5 Prozent auf 30 Prozent und wurde damit zum dominierenden Akteur.
ChatGPT-User, der API-basierte oder Browser-Nutzungen von ChatGPT im Zusammenhang mit Nutzerinteraktionen abbildet, verzeichnete einen explosionsartigen Anstieg von 2.825 Prozent bei den Anfragen, wodurch sein Anteil 1,3 Prozent erreichte.
PerplexityBot von Perplexity.ai, der die KI-Suche mit Echtzeit-Webdaten versorgt, zeigte das höchste Wachstum aller Crawler: Trotz eines geringen Anteils von 0,2 Prozent stiegen seine Roh-Anfragen um erstaunliche 157.490 Prozent.
Meta-ExternalAgent von Meta erreichte im Mai 2025 einen Anteil von 19 Prozent unter den AI-only Crawlern. Er wird mutmaßlich zum Training oder zur Feinabstimmung von LLMs verwendet.

Während einige KI-Crawler deutlich zulegten, erlebten andere einen deutlichen Rückgang.
Bytespider von ByteDance, der oft mit dem Training von Modellen wie Ernie oder TikTok-bezogener KI in Verbindung gebracht wird, verzeichnete einen deutlichen Rückgang. Sein Anteil sank von 22,8 Prozent auf nur noch 2,9 Prozent im Mai 2025, was einem Rückgang der Anfragen um 85 Prozent entspricht und ihn von Platz 2 auf Platz 8 zurückfallen ließ. Im Bereich der reinen KI-Crawler sank er von 42 Prozent auf 7 Prozent.
ClaudeBot von Anthropic, der zum Training und zur Aktualisierung des Claude KI-Assistenten dient, fiel ebenfalls, und zwar von 11,7 Prozent auf 5,4 Prozent des Gesamt-Traffics. Er verzeichnete einen Rückgang der Anfragen um 46 Prozent. Auch er sank im AI-only Ranking von 27 Prozent auf 21 Prozent.
Amazonbot, der Daten für die Such- und KI-Anwendungen von Amazon sammelt, und Applebot, der hauptsächlich für Siri und die Spotlight-Suche verwendet wird und möglicherweise auch in der KI-Entwicklung zum Einsatz kommt, verzeichneten ebenfalls Rückgänge bei ihrem Anteil und ihren Roh-Anfragen (-35 Prozent bzw. -26 Prozent).
Der Bingbot von Microsoft verzeichnete einen leichten Rückgang seines Anteils von 10 Prozent auf 8,7 Prozent, obwohl seine Roh-Anfragen bescheiden um 2 Prozent stiegen. Der FriendlyCrawler, dessen Zweck unklar ist, aber vermutlich für Suchergebnisse, Marktforschung oder Analysen genutzt wird, ist seit Mai 2025 nicht mehr unter den Top 20 gelistet und verzeichnete einen vollständigen Rückgang der Anfragen.
Angesichts dieser Veränderungen stehen Website-Betreiber vor neuen Herausforderungen bei der Kontrolle ihrer Inhalte. Traditionell nutzen sie die robots.txt-Datei, um Crawlern mitzuteilen, welche Inhalte indiziert werden dürfen und welche nicht. Daten vom Juni 2025 zeigen, dass etwa 14 Prozent der Top-10.000-Domains spezifische Anweisungen für KI-Bots in ihrer robots.txt hatten. Der GPTBot war dabei am häufigsten von Sperrungen betroffen, wurde aber paradoxerweise auch am häufigsten explizit zugelassen. Die Wirksamkeit von robots.txt bei der Verwaltung von KI-Crawlern ist jedoch umstritten, weil nicht alle Bots diese Regeln respektieren und viele Website-Besitzer unsicher sind, wie sie damit umgehen sollen.
Als Reaktion auf die zunehmende KI-Crawling-Aktivität gehen immer mehr Websites von passiven Signalen wie robots.txt zu aktiven Schutzmaßnahmen wie Web Application Firewalls über. Cloudflare, das Unternehmen, das diese Daten bereitstellt, hat sich ebenfalls auf die Entwicklung durchsetzbarer Kontrollen konzentriert, um Inhalte vor unautorisiertem Zugriff zu schützen.
Cloudflare bietet dazu jetzt ein erweitertes Modell: Dieses ermöglicht es nicht nur, KI-Crawler zu sperren oder zuzulassen, sondern es bietet eine dritte Variante. Websitebetreiber können mit Pay per Crawl eine festen Preis pro Zugriff festlegen.














![]()

![]()
![]()
![]()
