
Google Spam Update vom Juni ist schon beendet
Google hat das Spam Update vom Juni bereits abgeschlossen. Es dauerte nur zwei Tage.

Bild KI-generiert
Ein neuer Ansatz, der auf dem Modell SBERT basiert, soll bei Google das Erkennen von massenhaftem KI-Spam vereinfachen.

 Anzeige
Anzeige
Die wachsende Menge von AI Slop im Web ist ein Problem, auch für Google und YouTube. Ein Google Forscherteam aus Abhinav Mathur, Claire Liu, Kelvin Tan und Yifei Liu beschreibt in einer neu vorgestellten Arbeit ein System namens S-CTS (Scalable Cluster Termination System), mit dem massenhaft generierter KI-Spam besser erkannt werden soll. Im Zentrum steht eine Beobachtung: Angreifer erstellen oftmals ein Grundskript und lassen es von einem Generator tausendfach leicht abwandeln, verteilt über viele Konten. So entstehen unzählige Beiträge, die zwar im Wortlaut variieren, im Kern aber dasselbe sagen.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



Gegen diese Strategie versagen klassische Filter. Eine Prüfsumme oder ein einfacher Wortabgleich behandelt nämlich jede umformulierte Variante als völlig neuen Text. Das Google Team setzt deshalb an einer anderen Stelle an: bei der Bedeutung des Inhalts und beim koordinierten Verhalten der Konten. Für den Bedeutungsteil greift die Arbeit auf Text-Embeddings zurück, wie sie ein Modell vom Typ Sentence-BERT (kurz SBERT) liefert.
SBERT übersetzt einen Satz in einen Vektor, also in eine Liste von Zahlen. Sätze mit ähnlicher Bedeutung bekommen ähnliche Vektoren, selbst wenn sie kaum dieselben Wörter teilen. „Der Hund liegt auf der Couch" und „Auf dem Sofa schläft ein Hund" liegen im Zahlenraum dicht beieinander, obwohl die Wortwahl abweicht.
Solche Vektoren werden auch Embeddings genannt. Sie verwandeln Bedeutung in etwas Berechenbares. Damit lassen sich viele Texte gruppieren, Suchanfragen inhaltlich beantworten oder Dubletten finden, die sich hinter neuen Formulierungen verstecken. Vorgestellt wurde das Verfahren 2019 von Nils Reimers und Iryna Gurevych an der TU Darmstadt (Originalarbeit auf arXiv). Für die Spam-Abwehr ist eine Eigenschaft besonders wertvoll: SBERT misst, was ein Text bedeutet, und stört sich nicht daran, dass einzelne Wörter ausgetauscht wurden.
Das Verfahren baut auf BERT auf, einem Sprachmodell, das den Sinn von Wörtern aus ihrem Zusammenhang erschließt. BERT für sich genommen eignet sich nicht für den Vergleich vieler Texte, weil es immer zwei Sätze gemeinsam verarbeiten muss. Bei 10.000 Sätzen wären das rund 50 Millionen Vergleiche. Für eine Plattform mit Millionen täglicher Uploads ist das zu langsam.
SBERT löst das mit einer sogenannten siamesischen Architektur. Man verwendet zwei Kopien desselben Modells, die sich exakt dieselben Gewichte teilen. Jeder Satz wandert nur einmal hindurch und wird zu einem festen Vektor. BERT liefert dabei zunächst für jedes Wort einen eigenen Vektor; SBERT mittelt diese zu einem Satz-Vektor, dem sogenannten Mean-Pooling. Sind die Embeddings einmal berechnet, dauert ihr Vergleich nur noch Sekundenbruchteile. Statt vieler Stunden dauert der Abgleich so nur wenige Augenblicke, und das bei kaum schlechterer Genauigkeit.
Damit ähnliche Bedeutung auch wirklich zu nahen Vektoren führt, trainiert man das Modell auf Satzpaaren, die als bedeutungsgleich, widersprüchlich oder neutral markiert sind. Das Modell lernt, diese Beziehungen im Vektorraum nachzubilden. Im Betrieb misst dann die Kosinus-Ähnlichkeit den Winkel zwischen zwei Vektoren: Zeigen sie fast in dieselbe Richtung, liegt der Wert nahe 1 und die Texte gelten als inhaltlich verwandt; stehen sie quer zueinander, fällt er Richtung 0.
In S-CTS arbeiten zwei Bausteine zusammen. Der erste Baustein sucht nach koordinierten Konten-Gruppen. Er stützt sich auf Google-interne Signale wie Infrastruktur-Spuren und unnatürliche Verhaltensmuster und bildet daraus „Generation Clusters", also Gruppen von Konten, die wahrscheinlich vom selben Akteur oder Skript gesteuert werden.
Der zweite Baustein bewertet den Inhalt selbst. Genau hier kommen die Text-Embeddings ins Spiel. Damit lassen siuch wiederkehrende, schablonenhafte KI-Skripte erkennen, etwa in Videotiteln, Beschreibungen und Transkripten. Tauchen über viele Kanäle hinweg fast deckungsgleiche Skripte auf, deutet das auf einen automatisierten Generator hin. Ergänzt wird die Bedeutungsanalyse durch Verhaltenssignale wie den Upload-Takt eines Kanals.
Der eigentliche Vorteil liegt in der Kombination. Ein Kanal gerät erst dann ernsthaft unter Verdacht, wenn beide Spuren zusammenkommen: ein koordiniertes Konten-Cluster und gehäuft inhaltlich gleichartige, synthetisch wirkende Texte. Auffällige Fälle wandern in eine automatische Entscheidung, unklare Fälle gehen an menschliche Prüfer. Laut der Arbeit verkürzt das die Prüfzeiten deutlich, bei den Konten-Clustern um rund ein Drittel und bei der Inhaltsprüfung um etwa die Hälfte.
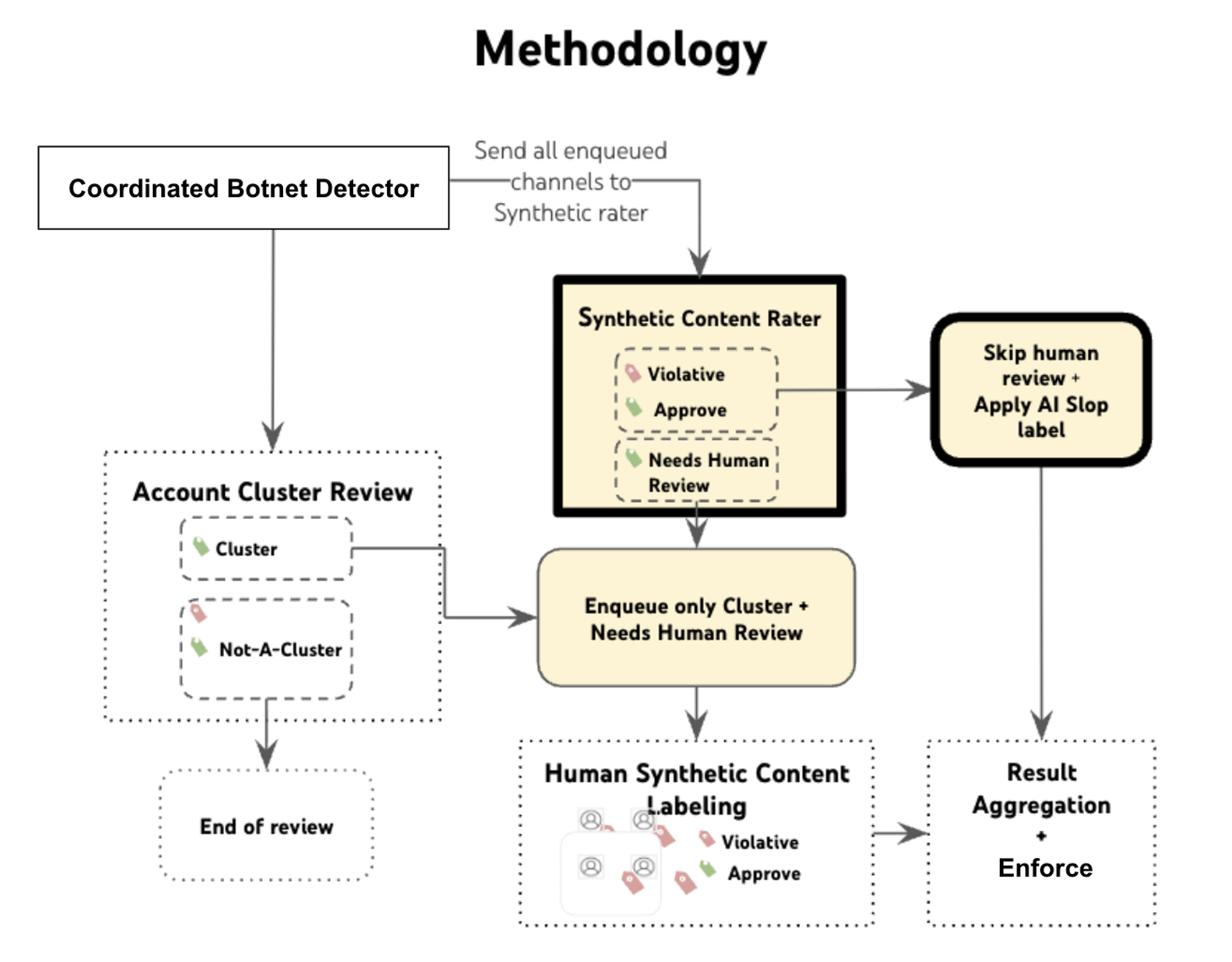
Abbildung: Google S-CTS-Workflow zum Erkennen von AI Slop. Quelle: Google
Hier lohnt eine klare Trennung. SBERT misst sehr verlässlich, ob zwei Texte inhaltlich nah beieinanderliegen. Es entscheidet aber nicht, ob ein einzelner Text von einer KI stammt oder gegen Regeln verstößt. Das Verfahren beantwortet die Frage „ähnlich oder nicht", nicht aber die Frage „echt oder gefälscht".
Inhaltliche Ähnlichkeit allein beweist nichts. Zwei seriöse Nachrichtenseiten, die über dasselbe Ereignis berichten, erzeugen ebenfalls nahe Embeddings, ohne Spam zu sein. Wer nur auf Textähnlichkeit setzt, läuft Gefahr, ehrliche Inhalte zum selben Thema mit abzustrafen. Der neue Ansatz umgeht das bewusst, indem er die Cluster-Bedingung vorschaltet: Die Textanalyse liefert einen Verdacht, die Entscheidung fällt erst zusammen mit dem Verhalten der Konten. Die Autoren betonen außerdem eine sehr niedrige Falsch-Positiv-Rate und setzen ihre Schwellen für automatische Sperren hoch an, um hochwertige KI-Beiträge nicht zu treffen.
Der Schwellenwert für die Ähnlichkeit braucht Fingerspitzengefühl. Liegt er zu hoch, rutschen geschickt umformulierte Varianten durch; liegt er zu niedrig, wandern harmlose Texte in dieselbe Gruppe. Diese Grenze sauber zu ziehen, ist die eigentliche Arbeit beim Einsatz.
Diese Frage trifft einen wunden Punkt vieler KI-Detektoren. Ein Detektor, der auf die Fingerabdrücke eines bestimmten Generators trainiert ist, steht nach dem nächsten Modellwechsel oft blind da und muss neu lernen.
SBERT steht hier besser da, weil es eine andere Frage stellt. Es schaut auf die Bedeutung des fertigen Textes und nicht auf das Modell dahinter. Ob das Skript von einem alten oder einem neuen Sprachmodell stammt, ändert nichts daran, dass sich tausend bedeutungsgleiche Varianten im Vektorraum sammeln. In diesem Sinn altert der Ansatz langsam.
SBERT lebt davon, dass Spam sich wiederholt. Sobald neuere Modelle Texte erzeugen, die inhaltlich wirklich breit streuen und keiner erkennbaren Schablone mehr folgen, schrumpfen die Gruppen, und der Ansatz hat weniger zu greifen. Angreifer können das gezielt ausreizen, indem sie ihren Texten themenfremdes Rauschen beimischen, um die Embeddings auseinanderzuziehen. Das Google-Team begegnet dem mit Beweglichkeit: Es passt seine Modelle laufend an neue Spam-Trends an und plant, künftig auch kryptografische Herkunftsnachweise wie C2PA und Wasserzeichen wie SynthID als zusätzliche Signale einzubeziehen. SBERT bleibt dabei ein Baustein unter mehreren.
Ja, und das ist sogar das naheliegendste Einsatzfeld. Bei reinem Text fällt der Umweg über Video, Audio und Transkript weg, der Inhalt liegt direkt vor.
Für deutschsprachige Inhalte gibt es passende mehrsprachige SBERT-Modelle, sodass sich der Ansatz über mehrere Sprachen eines Shops oder Portals hinweg verwenden lässt. Modelle und Beispiele finden sich in der Bibliothek sentence-transformers.


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
