
KI-Bots: Google rät von zusätzlichen Content-Direktiven in robots.txt ab
John Müller von Google rät von zusätzlichen Content-Direktiven in der robots.txt ab, die zur Steuerung von KI-Bots verwendet werden sollen.

Per Cloudflare kann man jetzt genauer steuern, was KI-Bots auf der Website machen dürfen. Man kann zum Beispiel Bots für die Suche freigeben und gleichzeitig Bots für das Trainieren von KI-Modellen sperren.


Das bekannte Content-Dilemma durch KI trifft viele Websitebetreiber: Möchte man mit den eigenen Inhalten im Web und in der Suche sichtbar sein und stellt diese öffentlich zur Verfügung, läuft man gleichzeitig Gefahr, dass diese Inhalte von KI-Anbietern zum Trainieren ihrer Modelle genutzt werden, und das ohne jegliche Gegenleistung. Der Traffic landet damit mehr und mehr bei den KI-Anbietern und weniger bei den Websites.
Cloudflare bietet jetzt eine Möglichkeit an, wie sich das ein wenig besser steuern und kontrollieren lässt. Dabei kann man nach drei verschiedenen Use Cases der Bots unterscheiden:
Während “Search” dem Aufbau von Suche-Indizes verbunden ist und damit auch Chancen schafft, aus der Suche Traffic zu erhalten, steht “Agent” für Echtzeit-Aktionen, die ein KI-Agent im Namen eines Nutzers durchführt, wie zum Beispiel das Ausfüllen eines Formulars oder das Aufgeben einer Bestellung. “Training” ist dagegen der Use Case, der von manchen nicht gewünscht ist: Hier greift der KI-Bot Informationen ab, um damit neue Modelle zu trainieren oder um bestehende Systeme zu verbessern.
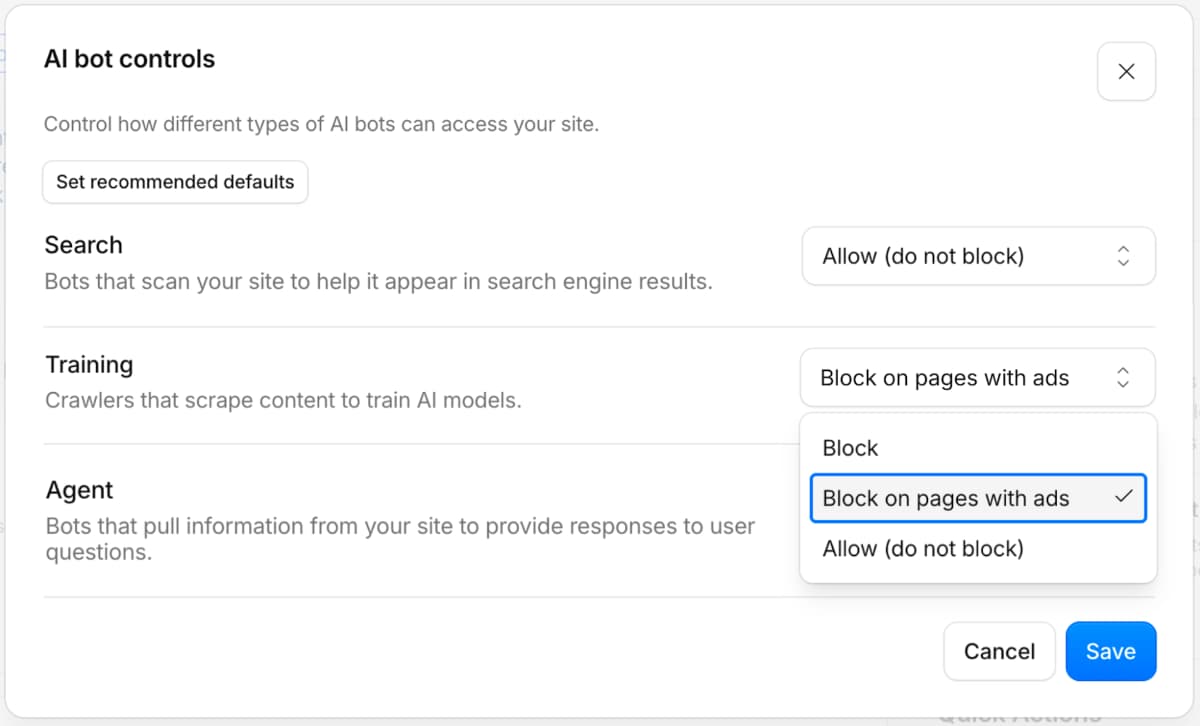
Möglich ist es außerdem, beim Sperren oder Freigeben nach Seiten mit und ohne Anzeigen zu unterscheiden. Dabei ist die Annahme, dass Seiten mit Anzeigen dazu gedacht sind, über Traffic zu monetarisieren, so dass diese eher für KI-Bots gesperrt werden, die Daten zum Trainieren sammeln.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



Ab dem 15. September werden für die drei Uses Cases neue Standardwerte gesetzt. Das gilt für alle neuen Domains, die zu Cloudflare hinzukommen. Die Kategorien “Agen” und “Training” werden dann für Seiten mit Anzeigen gesperrt, während “Search” für alle Seiten erlaubt bleibt.
Bei sogenannten Multi-Purpose-Crawlern, die mehrere Use Cases erfüllen, wird ab 15. September die jeweils strikteste Vorgabe für alle Uses Cases greifen. Ein Crawler, der zum Beispiel als Agent und für die Suche dient, wird dann keinen Zugriff mehr auf Seiten mit Werbung haben; es sei denn, man wählt andere Einstellungen.
Zusätzlich gibt es eine weitere Dimension, die man zur Steuerung der KI-Bots verwenden kann: Wie mit den abgerufenen Inhalten umgegangen wird. Hier gibt es drei Möglichkeiten:
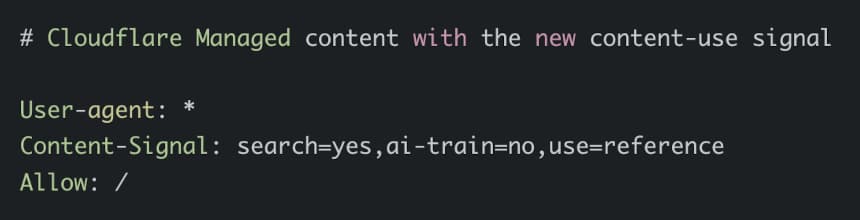
Dazu testet Cloudflare das neue Signal “use”, das in der robots.txt angegeben werden kann, zum Beispiel use=reference.
Hier ein Beispiel:
Und noch eine Änderung: Verifizierte Bots sind ab sofort nicht mehr automatisch per Default zugelassen. “Verifiziert” bedeutet, dass ein Bot sich selbst eindeutig durch eine Signatur, eine veröffentlichte IP-Liste oder per Reverse DNS identifiziert. Zudem darf es kein missbräuchliches Verhalten geben. Dazu gehört zum Beispiel, dass die Direktiven in der robots.txt beachtet werden.
Zur besseren Einordnung der KI-Bots stellt Cloudflare mit BotBase eine neue Datenbank zur Verfügung. Dort sind alle bekannten Bots enthalten.


Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
