Die Auswahl und das Ranking von Ergebnissen in der KI-Suche von Google erfolgen in einem mehrstufigen Prozess. Jeff Dean von Google erklärt, wie es funktioniert.
Die Vorstellung, dass moderne KI-Modelle das gesamte Internet in Echtzeit lesen und verstehen, ist eine faszinierende Illusion. Jeff Dean, Chief AI Scientist bei Google, räumt mit diesem Mythos auf und erklärt in einem Interview im KI-Podcast “Latent Space”, dass hinter den Antworten von KI-Suchmaschinen eine hochgradig optimierte, klassische Suchinfrastruktur steckt. Anstatt das Ranking überflüssig zu machen, sind Large Language Models eine zusätzliche Ebene, die auf bewährten Mechanismen zur Informationsfilterung aufbaut.
SEO-Beratung: Wir sind Ihre Experten
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.

Christian Kunz
SEO Experte

David Wulf
SEO Experte

Sven Häwel
Offpage-Experte
Der Trichter-Prozess: von Billionen zu Hunderten
Das Hauptproblem der KI-Suche ist die schiere Masse an verfügbaren Informationen. Es ist technisch unmöglich, einem Modell das gesamte Internet gleichzeitig als Kontext zur Verfügung zu stellen. Das wären viele Billionen von Token und würde damit das Kontextfenster jedes aktuellen KI-Modells übersteigen. Dean beschreibt die Lösung als einen mehrstufigen Filterprozess, der dem Nutzer lediglich die Illusion vermittelt, das Modell würde alles gleichzeitig im Blick haben. Der Prozess beginnt mit dem vollständigen Index des Webs, aus dem zunächst mit sehr leichtgewichtigen und schnellen Methoden eine grobe Auswahl von etwa 30.000 relevanten Dokumenten getroffen wird.
Diese immer noch viel zu große Menge wird anschließend durch spezielle Algorithmen drastisch reduziert. In dieser Phase kommen stärkere Ranking-Signale zum Einsatz, um die Qualität und Relevanz der Treffer zu bewerten. Erst am Ende dieses Trichters bleiben wenige Dutzend besonders elevante Dokumente übrig – Dean nennt beispielhaft die Zahl 117 –, die tatsächlich an das leistungsfähigste KI-Modell übergeben werden. Die Aufgabe der KI ist es dann nicht mehr, zu suchen, sondern diese kuratierten Informationen zu analysieren, zu synthetisieren und eine kohärente Antwort für den Nutzer zu generieren.
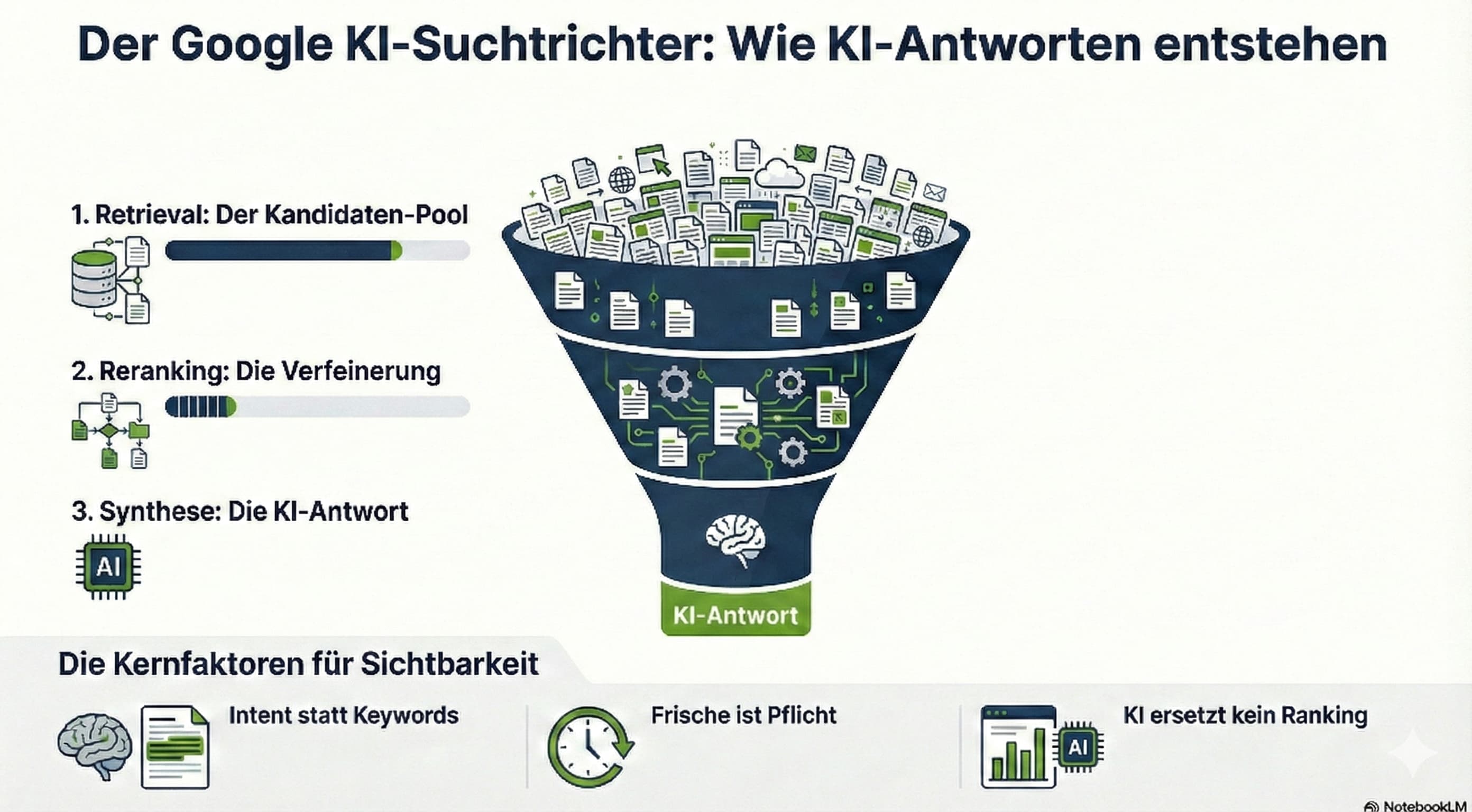 Bild generiert mit NotebookLM
Bild generiert mit NotebookLM
Vom Schlagwort zur Bedeutung
Ein entscheidender Fortschritt durch die Integration von LLMs in die Suche ist der Wandel vom reinen Wortabgleich hin zum semantischen Verständnis. Frühere Suchsysteme waren stark darauf angewiesen, dass die exakten Wörter der Suchanfrage auch auf der Webseite vorkamen. Zwar führte Google bereits im Jahr 2001 Systeme ein, die den Index im Arbeitsspeicher hielten, um Synonyme wie „Restaurant“ und „Bistro“ effizient verknüpfen zu können, doch der Ansatz blieb wortbasiert.
Die heutige LLM-basierte Repräsentation von Texten ermöglicht es hingegen, die thematische Relevanz eines Absatzes oder einer Seite zu verstehen, selbst wenn die gesuchten Begriffe dort gar nicht explizit auftauchen. Das System bewertet, ob ein Dokument den Kern der Anfrage trifft, anstatt nur Vorkommen von Zeichenketten zu zählen. Dies verschiebt den Fokus des Rankings von der Syntax hin zur tatsächlichen Intention des Nutzers und dem inhaltlichen Kontext.
Aktualität ist wichtig
Damit eine KI-Suche nützlich ist, muss das zugrundeliegende Ranking nicht nur relevant, sondern auch aktuell sein. Dean betont, dass die Geschwindigkeit, mit der der Suchindex aktualisiert wird, einer der wichtigsten Parameter für die Qualität der Ergebnisse ist. Veraltete Nachrichten im Index machen auch die beste KI-Antwort wertlos. Deshalb arbeiten im Hintergrund komplexe Systeme, die kontinuierlich entscheiden, wie oft bestimmte Seiten neu besucht werden müssen. Dabei wägt der Algorithmus ab, wie wahrscheinlich sich eine Seite ändert und wie wichtig diese Änderung für die Nutzer ist. Diese Infrastruktur garantiert, dass die Dokumente, die schließlich im Kontextfenster der KI landen, den neuesten Stand der Informationen widerspiegeln.
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige