

Warum Duplicate Content die KI-Sichtbarkeit beeinträchtigen kann - Tipps von Microsoft Bing
In einem Blogbeitrag erklärt Microsoft Bing, warum Duplicate Content die Sichtbarkeit in Suchmaschinen und KI einschränken kann.
 Das Sperren von URLs per robots.txt verhindert, dass Google Duplicate Content erkennen kann. Stattdessen sollte man zum Verhindern von Duplikaten in der Suche auf Canonical-Links setzen.
Das Sperren von URLs per robots.txt verhindert, dass Google Duplicate Content erkennen kann. Stattdessen sollte man zum Verhindern von Duplikaten in der Suche auf Canonical-Links setzen.
Es ist keine gute Idee, zur Vermeidung von Duplicate Content in den Google-Ergebnissen auf das Blockieren von URLs per robots.txt zu setzen. Zwar kann man dadurch bestimmte Pfade für Crawler wie den Googlebot sperren, doch verhindert man auf diese Weise auch, dass die Suchmaschine mögliche Duplikate erkennt und diese entsprechend behandelt.
Das zeigt ein aktuelles Beispiel: Ein Nutzer hatte per Twitter angefragt, ob er URL-Parameter per robots.txt blockieren solle, wenn gleichzeitig Canonical-Links gesetzt sind.
John Müller riet davon ab. Das Blockieren per robots.txt verhindere das Erkennen von Duplikaten. Besser sei es, den Suchmaschinen alle Inhalte zur Verfügung zu stellen und jeweils einen Canonical-Link zu setzen:
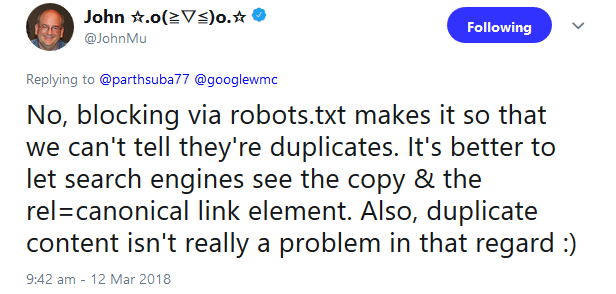
In diesem Fall sollte also auf Transparenz gegenüber Gooogle und anderen Suchmaschinen geachtet werden. Google ist inzwischen sehr gut dazu in der Lage, Duplicate Content zu erkennen und jeweils die URL mit der höchsten Relevanz anzuzeigen.
Unterstützten kann man dies durch die zusätzliche Angabe der bevorzugten URLs in der XML-Sitemap sowie durch eine saubere interne Verlinkung.
Titelbild © tumsasedgars - Fotolia.com




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
