

Weiterleitungen für Google und für Nutzer sollten gleich sein
Beim Aufsetzen von Redirects sollte man darauf achten, dass diese für die Nutzer und für Google gleich sind. Für eine besondere Nutzerbehandlung gibt es bessere Möglichkeiten.
 Wenn es auf einer Webseite zu längeren Redirect-Ketten kommt, kann es sein, dass Google diese ignoriert und gleich die finalen URLs crawlt.
Wenn es auf einer Webseite zu längeren Redirect-Ketten kommt, kann es sein, dass Google diese ignoriert und gleich die finalen URLs crawlt.
Redirect-Ketten können auf verschiedene Weisen entstehen. Oft sind Änderungen an der URL-Struktur die Ursache. Ein anderer Grund für verkettete Weiterleitungen ist die Kombination aus http bzw. https und WWW- und Nicht-WWW-URLs. So kann es sein, dass ein Link auf eine http-URL ohne WWW zeigt (http://beispiel.de), von wo aus man zunächst auf https und dann auf die WWW-Variante https://www.beispiel.de weitergeleitet wird.
Solche Weiterleitungsketten sind normalerweise kein Probllem für Google. Das hat Johannes Müller heute wieder bestätigt:
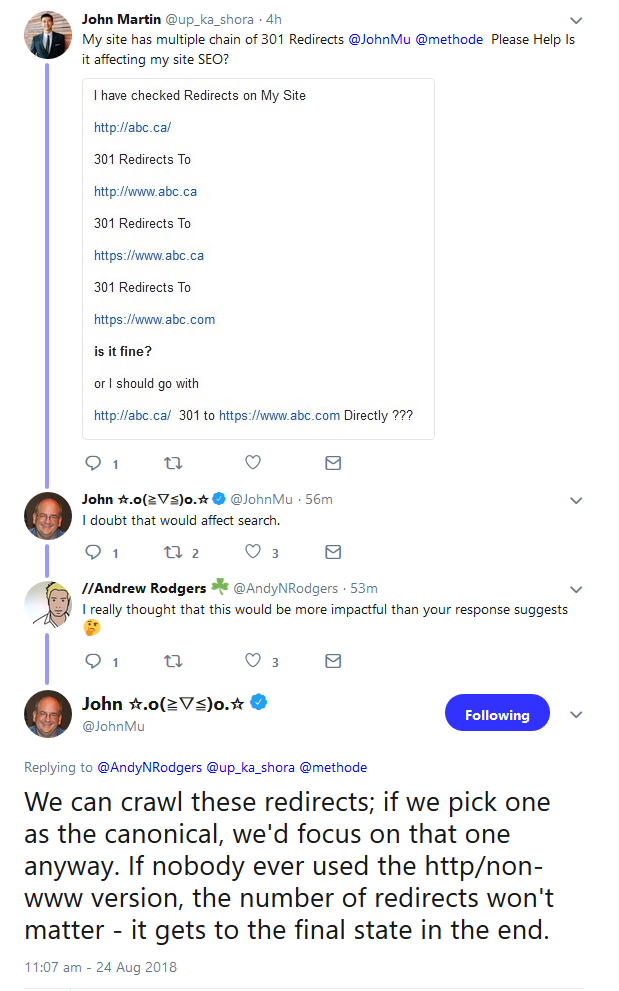
Müller teilte danach mit, dass Google solche Weiterleitungsketten irgendwann überspringe und gleich die finalen URLs aufrufe. Die Redirect-Ketten werden also bei zukünftigen Crawls nicht mehr abgerufen:
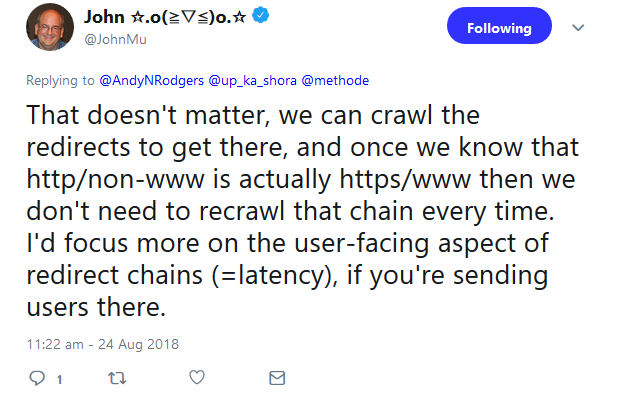
Müller betonte, bei Weiterleitungen sollte vor allem auf mögliche Latenzen und auf die Nutzer geachtet werden.
Google scheint also im Hinblick auf Weiterleitungen über eine gewisse Intelligenz zu verfügen, die dabei hilft, unnötige Sprünge beim Crawlen zu vermeiden.
Titelbild: Copyright bofotolux - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
