Durch die Wiederholung von Prompts, die sogenannte Prompt Repetition, sollen LLMs bessere Ergebnisse liefern. Das zeigt eine aktuelle Google Studie.
Die Studie von Yaniv Leviathan, Matan Kalman und Yossi Matias untersucht eine einfache, aber äußerst effektive Methode zur Leistungssteigerung von LLMs: die Wiederholung des Prompts. Anstatt eine Frage nur einmal zu stellen, wird der Eingabetext verdoppelt, sodass aus einer Eingabe wie "[Prompt]" die Form "[Prompt][Prompt]" wird.
SEO-Beratung: Wir sind Ihre Experten
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.

Christian Kunz
SEO Experte

David Wulf
SEO Experte

Sven Häwel
Offpage-Experte
Der Grund für die Wirksamkeit dieser Methode liegt in der Architektur der LLMs. Diese werden meist als kausale Sprachmodelle trainiert. Das bedeutet, dass frühere Token im Text nicht auf spätere Token reagieren können (Attention). Durch das wiederholte Einspeisen der Eingabe erhält jedes Token des Prompts die Möglichkeit, Informationen von allen anderen Token der Eingabe zu berücksichtigen. Das löst insbesondere Probleme, die durch die Reihenfolge von Informationen entstehen, wie etwa die Frage, ob zuerst der Kontext oder erst die Frage selbst im Text stehen sollte.
Leistungssteigerung ohne explizites logisches Schließen (Non-Reasoning)
Besonders starke und konsistente Leistungssteigerungen zeigt die Methode, wenn die Modelle kein Reasoning verwenden. Die Forscher testeten die Methode an sieben populären Modellen führender Anbieter, darunter verschiedene Versionen von Gemini, GPT, Claude und Deepseek, über diverse Benchmarks hinweg. Das Resultat: In 47 von 70 getesteten Kombinationen aus Benchmark und Modell gab es signifikante Verbesserungen, ohne dass die Leistung in einem einzigen Fall sank.
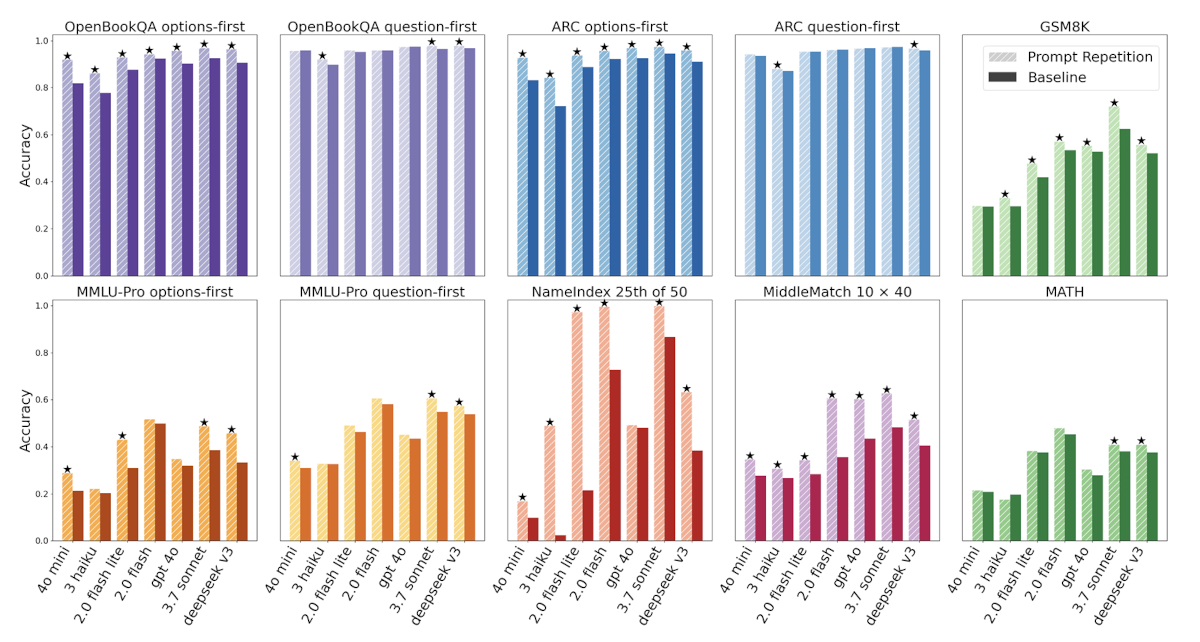
Besonders deutliche Leistungssteigerungen zeigten sich bei eigens für die Studie entwickelten Aufgaben wie dem "NameIndex", bei dem Modelle den x-ten Namen aus einer langen Liste heraussuchen müssen. Bei dieser Aufgabe stieg die Genauigkeit des Modells Gemini 2.0 Flash-Lite durch die einfache Wiederholung der Eingabe beispielsweise von 21,33 % auf 97,33 %.
Auswirkungen bei aktivierten Reasoning-Prozessen
Anders verhält es sich, wenn man die Modelle explizit dazu auffordert, Schritt für Schritt zu denken. In diesen Szenarien sind die Auswirkungen der Prompt-Wiederholung meist neutral bis nur leicht positiv (5 Verbesserungen, 1 Verschlechterung, 22 neutrale Ergebnisse). Die Autoren begründen das damit, dass Modelle im Reasoning-Modus dazu tendieren, von sich aus Teile der Nutzeranfrage in ihrer Ausgabe zu wiederholen, um ihren Gedankengang zu strukturieren, wodurch der Effekt der manuellen Wiederholung vorweggenommen wird.
Effizienz und Variationen der Methode
Ein entscheidender Vorteil der Prompt-Wiederholung ist ihre hohe Effizienz. Weil die wiederholten Textbausteine in der sogenannten "Prefill"-Phase verarbeitet werden, welche stark parallelisierbar ist, führt die Methode weder zu längeren Textausgaben der Modelle noch zu längeren Antwortzeiten (Latenzen). Eine Ausnahme bilden lediglich sehr lange Anfragen bei den Modellen von Anthropic.
Die Forscher testeten zudem verschiedene Variationen: Eine dreifache Wiederholung der Eingabe ("Prompt Repetition ×3") erwies sich bei bestimmten Aufgaben als noch leistungsstärker als die einfache Wiederholung. Ein Kontrolltest, bei dem die Eingabe künstlich mit Punkten aufgefüllt wurde, um dieselbe Textlänge zu erreichen ("Padding"), brachte hingegen keine Verbesserungen.
Das belegt, dass der Erfolg tatsächlich auf der Wiederholung der inhaltlichen Informationen beruht. Weil die Prompt-Wiederholung auch das Format der Antworten nicht verändert, eignet sie sich hervorragend als Standardeinstellung für viele Modelle und Aufgaben im Non-Reasoning-Bereich und lässt sich nahtlos in bestehende Systeme integrieren.
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige