

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
 Der Googlebot folgt beim Crawlen nicht automatisch der Verzeichnisstruktur in URLs, sondern ist zum Abruf der Seiten auf Links angewiesen. Unterstützend können XML-Sitemaps wirken.
Der Googlebot folgt beim Crawlen nicht automatisch der Verzeichnisstruktur in URLs, sondern ist zum Abruf der Seiten auf Links angewiesen. Unterstützend können XML-Sitemaps wirken.
Eine interessante Information zum Vorgehen beim Crawling durch den Googlebot gab es heute: Nur Seiten, die verlinkt sind, werden aufgerufen. Dagegen nutzt der Googlebot normalerweise nicht die in der URL-Struktur enthaltenen Pfade und Verzeichnisebenen, um neue Seiten zu entdecken.
Ein Nutzer hatte per Twitter gefragt, ob sich der Crawler von einem Verzeichnis in URLs zum nächsten vorarbeite, also zum Beispiel von der URL "/schuhe/turnschuhe/" auf die nächst höhere Ebene "/schuhe/". John Müller antwortete, dies geschehe, aber nur dann, wenn die Ebenen verlinkt seien - ansonsten normalerweise nicht:
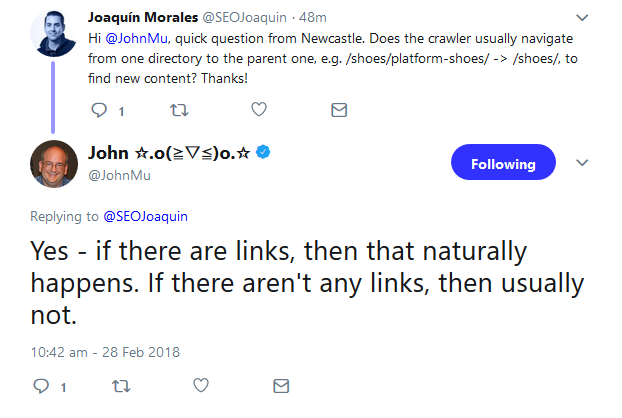
Das zeigt: Eine durchdachte URL-Struktur mit Kategorien, Unterkategorien und Landing Pages alleine stellt noch nicht sicher, dass Google alle wichtigen Seiten crawlt. Man muss auch dafür sorgen, dass die Seiten durch interne Links miteinander verbunden sind, oder dass es externe Links auf die Seiten gibt. Zusätzlich sollten alle wichtigen URLs in einer XML-Sitemap für Google bereitgestellt werden.
Titelbild: Google



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
