

Google: Auch automatisch per KI erzeugte können gute Rankings erzielen
Google stellt klar, dass KI-Inhalte nicht automatisch gegen die Richtlinien für die Suche verstoßen. Auch bei automatisch erzeugten Inhalten kommt es auf EEAT an.
 Google rückt von seiner grundsätzlichen Ablehnung gegenüber automatisch erzeugten Inhalten ab. Das liegt möglicherweise auch daran, dass Google entsprechende Techniken selbst nutzen möchte.
Google rückt von seiner grundsätzlichen Ablehnung gegenüber automatisch erzeugten Inhalten ab. Das liegt möglicherweise auch daran, dass Google entsprechende Techniken selbst nutzen möchte.
Googles Webmaster-Richtlinien schließen automatisch erzeugte Inhalte aus. Das Verwenden entsprechender Texte auf einer Webseite kann damit zu einer Abstrafung durch Google führen. in diesem Zusammenhang nennt Google die folgenden Inhalte:
Trotz dieser scheinbar grundlegenden Ablehung automatisch erzeugten Texten gegenüber hat Google offenbar ein Interesse daran, selbst solche Inhalte zu erzeugen. Wie das funktionieren kann, zeigen zwei wissenschaftliche Arbeiten, die sich mit der Zusammenfassung von Informationen aus bestehenden Texten beschäftigen. Die Titel dieser Arbeiten lauten "Faithful to the Original: Fact Aware Neural Abstractive Summarization" und "Generating Wikipedia by summarizing long sentences".
In beiden Texten wird beschrieben, wie mittels extrahierender Zusammenfassung, also der Nutzung von bestimmten Auszügen von Texten, sowie mittels abstrahierender, also schlussfolgernder Zusammenfassung neue Inhalte geschaffen werden können. Dabei liegt ein Schwerpunkt auf der Vermeidung von fehlerhaften Fakten, wie sie bei bisher verwendeten Ansätzen der Textzusammenfassung oftmals entstanden sind.
Bereits heute nutzt Google die extrahierende Zusammenfassung, um die Texte für Featured Snippets zu erzeugen. Dabei werden die gesamten Inhalte einer Webseite auf wenige Zeilen Text mit den wichtigsten Aussagen reduziert.
Weitere Einsatzmöglichkeiten solcher Techniken bieten sich an: Vor allem im Bereich der gesprochenen Suche (Voice Search), wie sie bei der Nutzung von digitalen Assistenten üblich ist, kann die Zusammenführung von Informationen aus verschiedenen Quellen in eine Antwort hilfreich sein.
Theoretisch könnte Google zukünftig dazu übergehen, nur noch selbst erzeugte Inhalte als Suchergebnisse anzuzeigen, die aus den Inhalten verschiedener Webseiten generiert wurden. Zwar wird ein solcher Vorschlag in keiner der erwähnten wissenschaftlichen Arbeiten angesprochen, doch wenn eine solche Möglicheit besteht, warum sollte Google sie nicht ergreifen? Zumindest in bestimmten Fällen wie den erwähnten Voice Searches ist ein solches Szenario wahrscheinlich.
Bemerkenswert ist der Sinneswandel, der sich bei Google scheinbar im Hinblick auf automatisch erzeugte Inhalte vollzogen hat. Danny Sullivan schreibt dazu auf Twitter, es gebe bereits viele automatisch erzeugte Inhalte. Die Google-Richtlinien solle nicht dazu dienen, solche Inhalte als schlecht zu kennzeichnen. Es gehe darum, Missbrauch unter Einsatz automatisch erstellter Inhalte zu vermeiden:
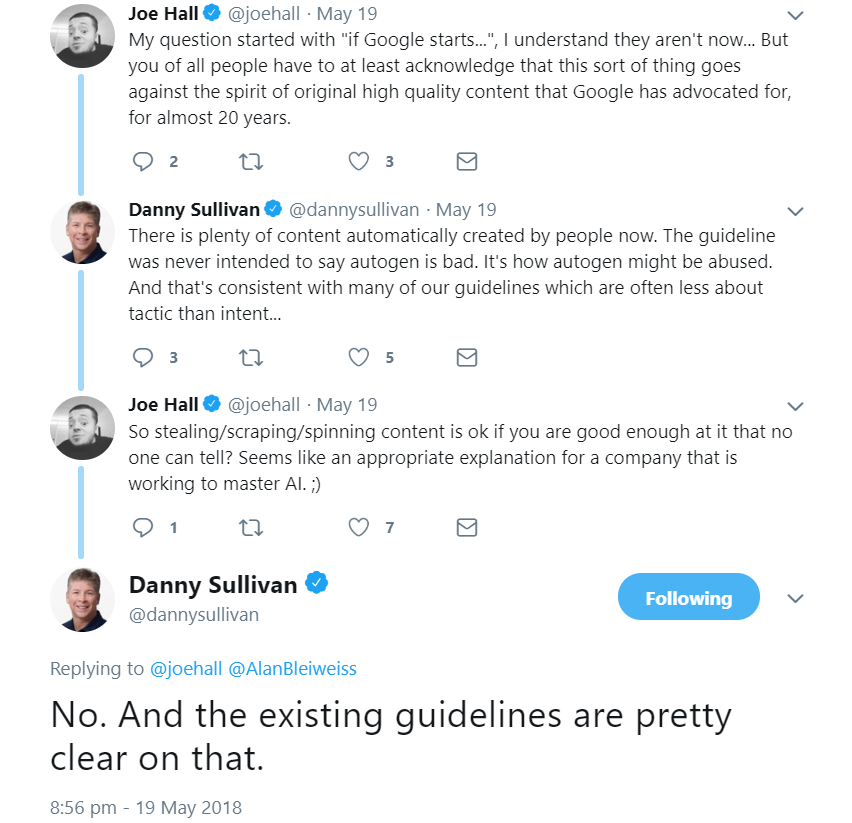
Wo liegt aber jetzt genau die Grenze zwischen "guten" und "schlechten" automatisch erzeugten Inhalten? Diese Antwort bleibt Google schuldig. Sollte es zukünftig auch für normale Webseitenbetreiber möglich sein, hochwertige Inhalte automatisch zu generieren, die alleine durch die Zusammenfassung von Inhalten verschiedener Quellen einen Mehrwert bieten, warum sollten solche Inhalte nicht auch in den Suchergebnissen erscheinen?
Eine weitere Frage, die sich daraus ergibt, betrifft das Urheberrecht: Inwieweit verletzt die Zusammenfassung verschiedener Quellen ohne deren Nennung die Rechte der Urheber, und wie lässt sich ein möglicher Verstoß aufdecken, wenn die erzeugten Texte keine Rückschlüsse mehr auf die Originale erlauben?
Titelbild: Google




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
