

Google behandelt Hashtags auf Webseiten wir normale Worte
Hashtags auf Webseiten haben für Google keine besondere Bedeutung, sondern werden wie normale Worte behandelt.
 Fragment-URLs, die mit einem '#' unterteilt sind, lassen sich nicht per robots.txt für das Crawlen durch Google und andere Suchmaschinen sperren. Aber es gibt eine Alternative.
Fragment-URLs, die mit einem '#' unterteilt sind, lassen sich nicht per robots.txt für das Crawlen durch Google und andere Suchmaschinen sperren. Aber es gibt eine Alternative.
Sogenannte Fragment-URLs erkennt man am Hash-Zeichen, mit dem ein Teil der URL abgegrenzt wird. Durch den Bereich hinter dem Hash oder Doppelkreuz wird auf einen bestimmten Teil des aufgerufenen Dokuments verwiesen. Wird ein solcher Bereich zu einer URL hinzugefügt, findet kein gesonderter Aufruf an den Server statt.
In seltenen Fällen kann es geschehen, dass Google Fragment-URLs indexiert und in den Suchergebnissen anzeigt. Möchte man dies vermeiden, hilft zumindest die robots-txt-Datei nicht weiter, denn mit ihr lassen sich solche URLs nicht gegen das Crawlen sperren. Das bestätigte John Müller per Twitter:
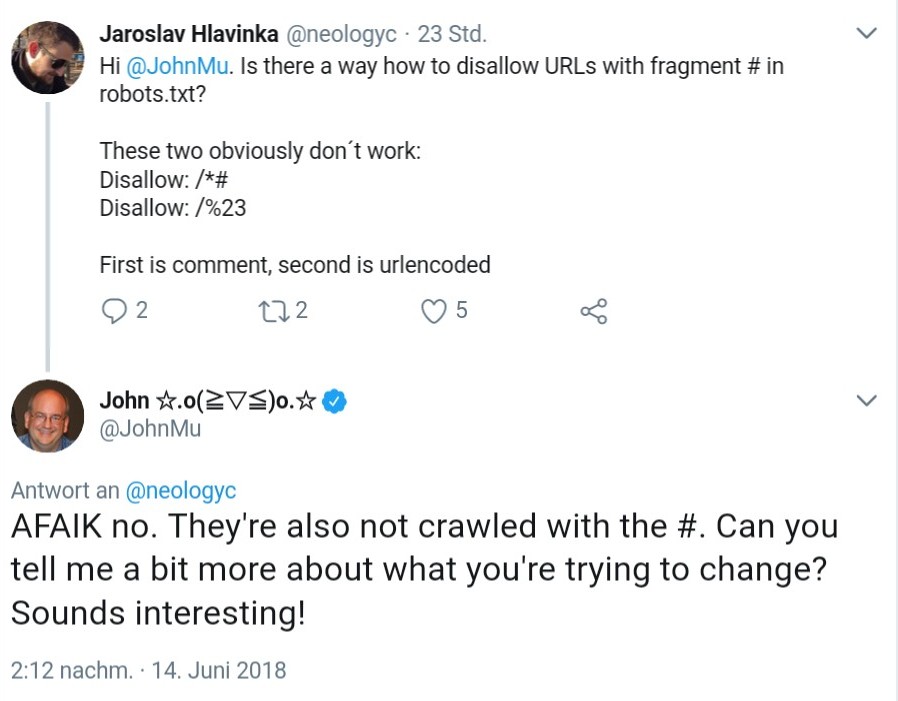
Als Alternative schlägt Müller vor, per JavaScript ein "Noindex"-Robots-Tag zu setzen. Zuvor sollte allerdings geprüft werden, ob das Indexieren solcher Fragment-URLs tatsächlich Nachteile bringt, oder ob es nicht einfach zugelasssen werden sollte.
Titelbild: Copyright Photoco - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
