

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 Wenn es beim Abruf der robots.txt einer Website dauerhaft zu Serverfehlern kommt, kann dies das Crawlen durch Google beeinträchtigen.
Wenn es beim Abruf der robots.txt einer Website dauerhaft zu Serverfehlern kommt, kann dies das Crawlen durch Google beeinträchtigen.
Google prüft vor dem Crawlen einer Website deren robots.txt. Darin sind Informationen darüber enthalten, welche URLs und Verzeichnisse von den Crawlern der Suchmaschinen abgerufen werden dürfen und welche nicht.
Kommt es beim Abruf der robots.txt aber zu Problemen, kann dies das Crawlen der Website beeinträchtigen. Google kann das Crawlen sogar komplett einstellen und beim Andauern der Probleme die Website aus dem Index entfernen.
Dies war auch Thema auf der gestrigen Google Webmaster Conference. Darin wurde genauer erklärt, wie genau sich die verschiedenen Antworten beim Abruf einer robots.txt auf das Crawlen auswirken können:
Es ist also nicht schlimm, wenn es keine robots.txt gibt und der Server mit einem Status 404 antwortet. Auch vorübergehende Serverfehler sind nicht dramatisch.
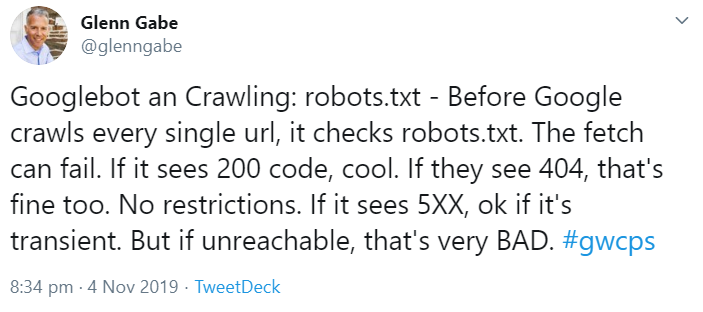
Der letzte Fall, also dauerhafte Serverfehler beim Versuch, die robots.txt anzurufen, kann aber dazu führen, dass Google das Crawlen einstellt und eventuell sogar die URLs der betroffenen Website aus dem Index entfernt.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
