

AI Brand Authority Index: neue Datenbank für Sichtbarkeit von Marken in Google Gemini
Über eine neue Datenbank lässt sich jetzt der AI Brand Authority Index abrufen: die Sichtbarkeit von Marken in Google Gemini.
 Auch Seiten, die Google aufgrund der robots.txt nicht crawlen kann, sind in der Lage, PageRank zu empfangen. In umgekehrter Richtung funktioniert das allerdings nicht.
Auch Seiten, die Google aufgrund der robots.txt nicht crawlen kann, sind in der Lage, PageRank zu empfangen. In umgekehrter Richtung funktioniert das allerdings nicht.
Wenn eine Webseite für Google per robots.txt gesperrt ist, kann der Googlebot die Seite nicht crawlen. Dennoch kann es sein, dass Google auf die Seite stößt, und zwar über Links von anderen Seiten.
Bekanntlich übertragen Links PageRank zwischen einzelnen Dokumenten und Seiten im Netz. Und das gilt auch dann, wenn die verlinkte Seite per robots.txt gesperrt ist. Das erklärte Johannes Müller von Google jetzt per Twitter.
Umgekehrt gilt das jedoch nicht: Eine per robots.txt gesperrte Seite kann keinen PageRank übertragen, denn um die auf der Seite vorhandenen Links zu erkennen und zu werten, müsste Google die Seit crawlen:
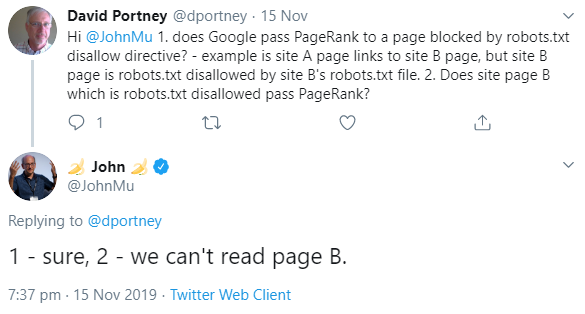
Aus diesem Grund sollte man sich immer gut überlegen, ob man Seiten per robots.txt sperren möchte, denn das bedeutet auch, dass Google interne Links auf dieser Seite nicht erkennt, was unter Umständen zu Nachteilen für die gesamte Website führen kann, denn interne Links helfen Google dabei, die Gesamtsruktur einer Website zu erfassen und möglichst viele der vorhandenen Ressourcen zu crawlen.




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
