

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
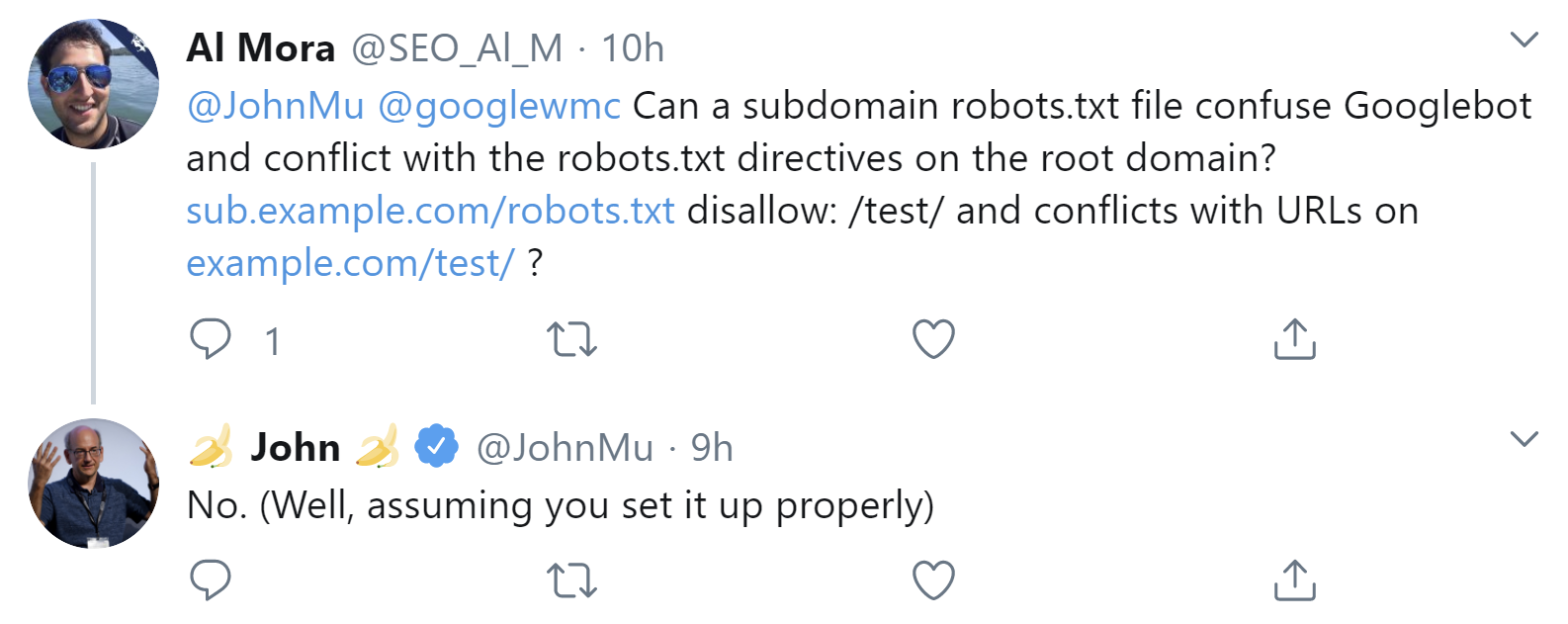
 Das Verwenden einer eigenen robots.txt für Subdomains hat keine störenden Auswirkungen auf die Bewertung der robots.txt der Hauptdomain durch Google, wenn sie richtig aufgesetzt ist.
Das Verwenden einer eigenen robots.txt für Subdomains hat keine störenden Auswirkungen auf die Bewertung der robots.txt der Hauptdomain durch Google, wenn sie richtig aufgesetzt ist.
Es ist möglich, eine robots.txt nicht nur auf Ebene der Hauptdomain zu verwenden, sondern auch für Subdomains eigenständige robots.txt-Dateien einzubinden. Auf diese Weise lässt sich für die jeweiligen Subdomains bestimmen, welche Seiten und Verzeichnisse von den einzelnen Crawlern abgerufen werden dürfen und welche nicht.
Durch die Verwendung von verschiedenen robots.txt-Dateien für Haupt- und Subdomains sollte es für den Googlebot keine Probleme geben. Das bestätigte Johannes Müller per Twitter auf Anfrage. Er schrieb aber auch, das gelte dann, wenn die Dateien korrekt eingesetzt würden:
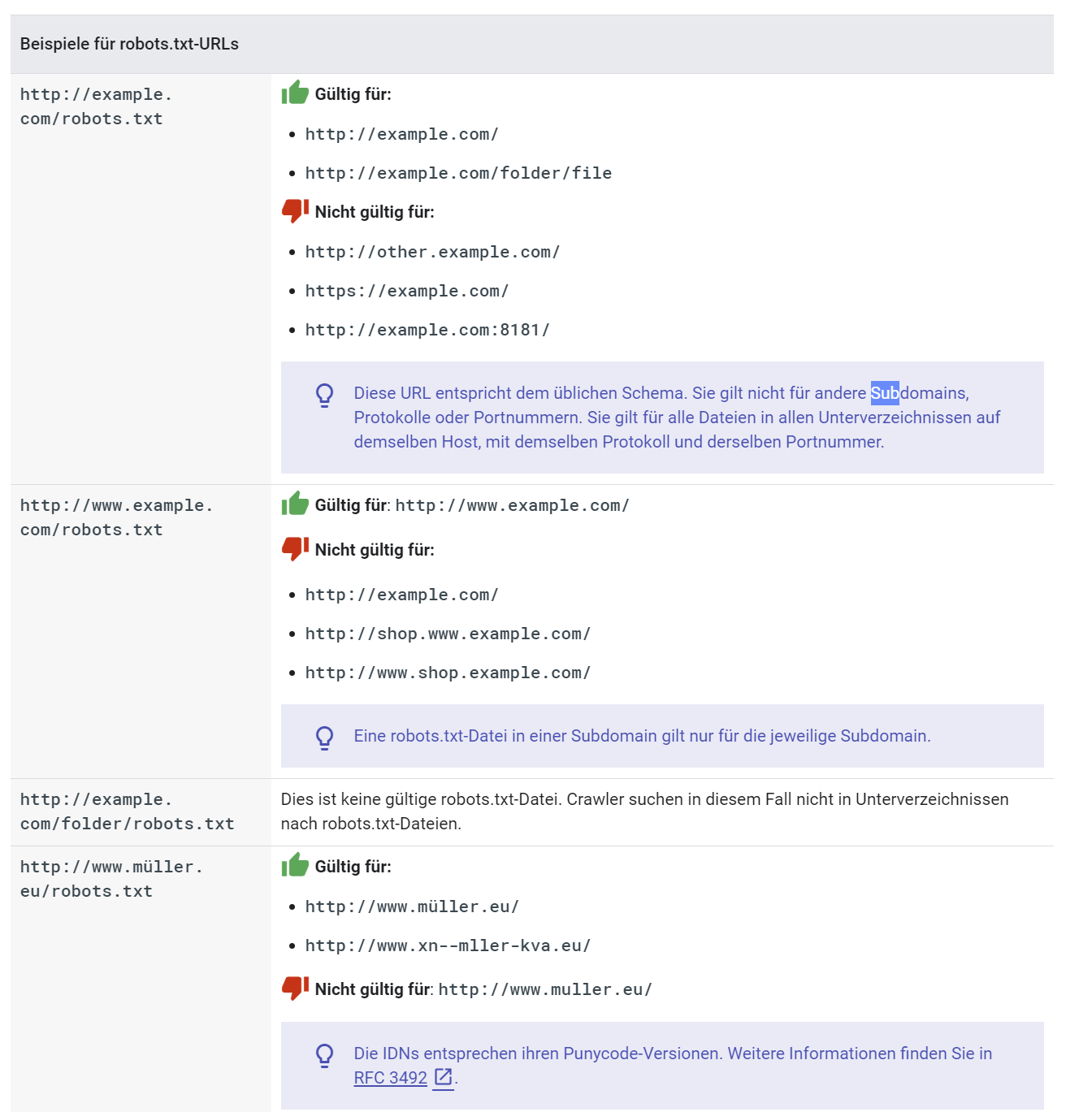
Dabei ist auch zu beachten, dass zum Beispiel eine robots.txt, die für die www-Variante einer Domain aufgesetzt wird, nicht für die Nicht-www-Variante der Domain gilt, weil "www" auch eine Subdomain darstellt. So gilt zum Beispiel die robots.txt unter https://www.example.com/robots.txt nicht für die Domain https://example.com.
Zu beachten ist außerdem, dass Google robots.txt-Dateien in Verzeichnissen nicht beachtet. So wird zum Beispiel die Datei https://example.com/verzeichnis/robots.txt keinen Einfluss haben.
Nachfolgend einige Beispiele aus der Google-Hilfe zu robots.txt:
Ob es sinnvoll ist, für einzelne Subdomains eigenständige robots.txt-Dateien zu verwenden, muss jeder selbst entscheiden. Nachteilig kann der erhöhte Pflegeaufwand sein. Zudem ist es schwieriger, einen Gesamtüberblick aller erlaubten und gesperrten Verzeichnisse einer Website zu erhalten.
Vorteilhaft kann dieser Ansatz vor allem für Websites sein, bei denen die Inhalte der Subdomains unabhängig voneinander sind.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
