

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 Es gibt bestimmte Sonderfälle, in denen Google Inhalte von URLs indexiert, obwohl diese per robots.txt gesperrt sind.
Es gibt bestimmte Sonderfälle, in denen Google Inhalte von URLs indexiert, obwohl diese per robots.txt gesperrt sind.
Das Setzen von "disallow" in der robots.txt für eine URL bewirkt normalerweise, dass Google diese URL nicht crawlt und auch nicht indexiert. Dennoch kann es passieren, dass Google Snippets für solche URLs in den Suchergebnissen anzeigt, zum Beispiel, wenn es externe Links auf die betreffenden URLs gibt. In der Regel erscheint im Snippet dann aber nur die URL ohne Text bzw. Description, weil das Crawlen per robots.txt blockiert ist.
Es gibt aber Sonderfälle, in denen Google auch Inhalte von blockierten URLs indexiert. Das bestätigte Johannes Müller auf Nachfrage per Twitter. Er bezog sich damit auf einen früheren Blogpost von Google zum Thema nicht mehr unterstützte Regeln in der robots.txt. Darin ist zu lesen:
"Search engines can only index pages that they know about, so blocking the page from being crawled usually means its content won’t be indexed."
Es ging um den Begriff "usually", der besagt, dass es Ausnahmen von der Regel gibt, dass Inhalte von blockierten Seiten nicht indexiert werden. Müller nennt beispielhaft die folgenden Aussagen:
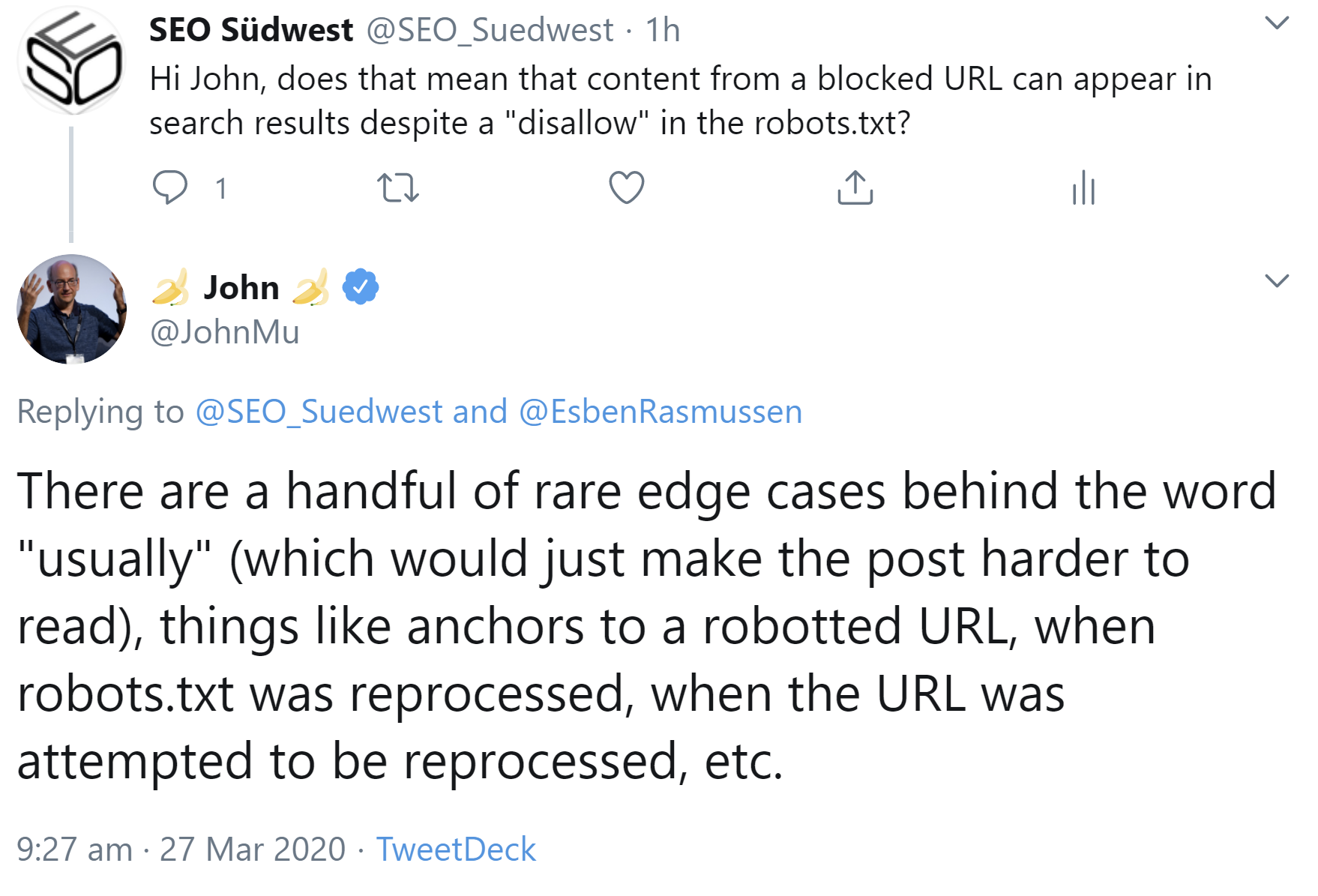
Es gibt also keine Garantie dafür, dass Inhalte von per robots.txt gesperrten URLs nicht in der Suche erscheinen. Wer das erreichen möchte, sollte die entsprechenden URLs auf "noindex" setzen.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen









![]()

![]()
![]()
![]()
