

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 In der robots.txt bestimmt nicht die Reihenfolge, welche Regel von Google und anderen Suchmaschinen befolgt wird, sondern es gilt: Eine spezifischere Regel sticht eine allgemeinere Regel.
In der robots.txt bestimmt nicht die Reihenfolge, welche Regel von Google und anderen Suchmaschinen befolgt wird, sondern es gilt: Eine spezifischere Regel sticht eine allgemeinere Regel.
Manche robots.txt-Dateien sind recht komplex aufgebaut. Neben Sonderbehandlungen für verschiedene User Agents enthalten sie auch Regeln für unterschiedliche Pfade und unterschiedliche URLs, zum Teil erweitert um reguläre Ausdrücke, um unterschiedliche Konstellationen abzudecken.
Dabei kann es leicht unübersichtlich werden. Häufig weiß man dann nicht mehr genau, welche Direktive zur Anwendung kommt und welche nicht. In der Folge kann es zu ungewünschten Folgen kommen, zum Beispiel, dass URLs blockiert werden, die eigentlich gecrawlt werden sollen.
Für solche Fälle gibt es in der Google Search Console den Robots.txt-Tester. Damit kann man pro URL prüfen, ob diese durch eine robots.txt gesperrt ist oder nicht.
Hilft auch dieses Tool nicht weiter, so bleibt als weitere Möglichkeit, sich direkten Rat bei Google zu besorgen. So war es in einem aktuellen Fall, in dem ein Nutzer eine Anfrage an Johannes Müller stellte. Es ging dabei um das Blockieren bzw. Nicht-Blockieren von URLs, die den Term "robots.txt" enthalten.
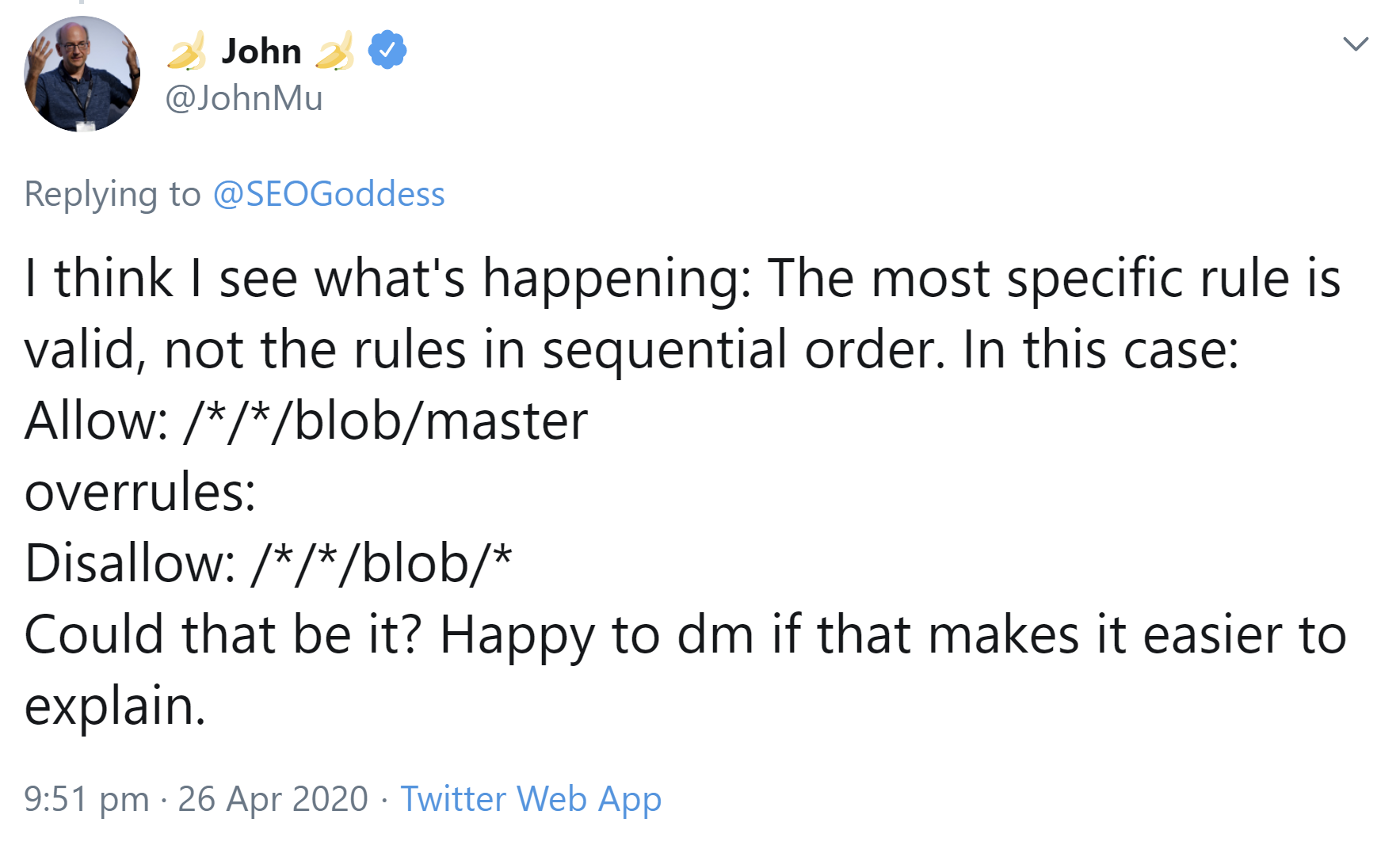
In diesem Zusammenhang gab Müller einen interessanten Tipp: Nicht die Reihenfolge der Regeln innerhalb der robots.txt ist entscheidend, sondern die jeweils speziellste Regel greift. Das zeigt das folgende Beispiel:
Allow: /*/*/blob/master sticht
Disallow: /*/*/blob/*.
Das muss beim Erstellen von Regeln für eine robots.txt berücksichtigt werden.
Generell sollte man die robots.txt so kurz und übersichtlich wie möglich halten und so wenige URLs wie möglich sperren und dies auch nur dort, wo es wirklich notwendig ist. Damit reduziert man das Risiko unnötiger Fehler.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
