

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
 Es gibt verschiedene Meldungen darüber, dass Google das Crawlen mancher Websites seit dem 11. November deutlich reduziert haben soll. Vermutet wird ein Zusammenhang mit 304-Redirects. Andere Stichproben zeigen dagegen keine Auffälligkeiten.
Es gibt verschiedene Meldungen darüber, dass Google das Crawlen mancher Websites seit dem 11. November deutlich reduziert haben soll. Vermutet wird ein Zusammenhang mit 304-Redirects. Andere Stichproben zeigen dagegen keine Auffälligkeiten.


Damit Google neue und geänderte Inhalte entdecken und indexieren kann, ist das Crawlen von Websites unverzichtbar. Gerade bei großen Websites mit vielen URLs und vielen Änderungen kann es daher problematisch werden, wenn Google die Crawling-Rate reduziert. Und genau das könnte seit einigen Tagen der Fall sein. Dafür sprechen verschiedene Meldungen in sozialen Netzwerken.
So schreibt zum Beispiel Nutzer Olivier, einer der Gründer des Tools Seolyzer, auf Twitter, Google habe seine Crawl-Rate seit dem 11. November drastisch reduziert:

Manche vermuten einen Zusammenhang zwischen Aufrufen, die vom Server mit dem HTTP-Status 304 beantwortet werden, und dem Absenken der Crawling-Rate. Der Status 304 steht für "Not Modified" und kann dann gesendet werden, wenn sich das abgerufene Dokument seit dem letzten Abruf nicht geändert hat. Dazu werden Datum und Uhrzeit verwendet, die im HTTP Header im Feld "If-Modified-Since" angegeben sind. Das entsprechende Dokument wird dann nicht vom Server an den Client gesendet.
John Müller von Google hatte bereits im Jahr 2018 erklärt, dass sich der Status 304 nicht auf die Crawl-Rate auswirkt. In der offiziellen Google-Dokumentation steht zu lesen, dass der Status 304 keine Auswirkungen auf die Indexierung habe. Vom Crawlen steht dort allerdings nichts:
"Der Googlebot signalisiert der Indexierungspipeline, dass sich der Inhalt seit dem letzten Crawling nicht geändert hat. In der Indexierungspipeline werden Signale für die URL möglicherweise neu berechnet. Ansonsten hat der Statuscode keine Auswirkung auf die Indexierung."
Allerdings zeigt ein weiterer Tweet des oben genannten Nutzers, dass gerade für URLs mit Status 304 das Crawling im betrachteten Zeitraum deutlich gesunken ist:

John Müller äußerte auf Twitter eine andere Theorie. Wird die gesunkene Crawl-Rate durch Fake Googlebots verursacht, die auf einmal ihr Crawlen eingestellt haben, aus Sorge, entlarvt zu werden? Immerhin hatte Google zuletzt eine Liste der IP-Adressen veröffentlicht, die Google zum Crawlen verwendet, was die Verifizierung des Googlebots vereinfacht.
Gegen diese Theorie spricht jedoch die Beobachtung eines Nutzers, der eine Reduzierung des Crawlens von eben diesen Google-IPs festgestellt hat:
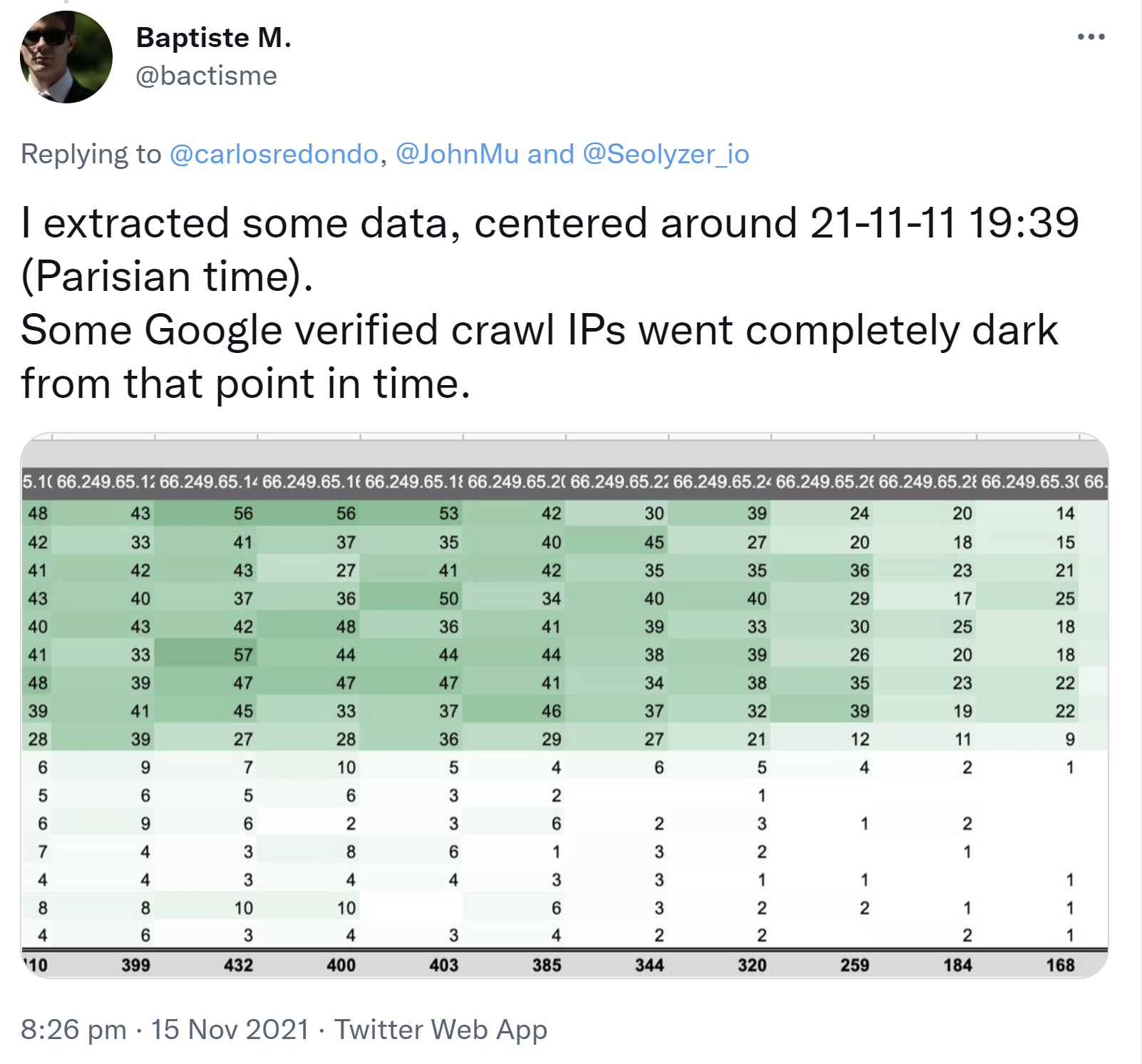
Was auch immer der Grund für die beobachteten Änderungen sein mag: Von Google gibt es bisher keinerlei offizielle Bestätigung zu möglichen Crawling- oder Indexierungsproblemen.
Wie viele Abrufe der Googlebot für eine Website durchführt, kann man zum Beispiel in der Google Search Console im Bereich "Einstellungen" sehen. Und auch in den Logfiles des Webservers lassen sich die Aufrufen nachverfolgen.
Bei einigen stichprobenartigen Kontrollen für verschiedene Websites in der Google Search Console zeigten sich zumindest keinerlei Besonderheiten, welche für einen Rückgang des Crawlens sprechen. Teilweise gab es sogar eine deutliche Zunahme des Crawlens zum 11. November.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
