

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.

Änderungen an der robots.txt, auch solche, welche die gesamte Website betreffen, wirken sich nicht sofort auf alle URLs aus, sondern werden nach und nach angewandt.


Ein klassischer und gleichzeitig fataler Fehler in der robots.txt einer Website ist es, aus Versehen alle URLs per disallow: / für das Crawlen der Suchmaschinen zu sperren.
Wir bringen gemeinsam Ihre Website nach vorne. Profitieren Sie von jahrelanger SEO-Erfahrung.



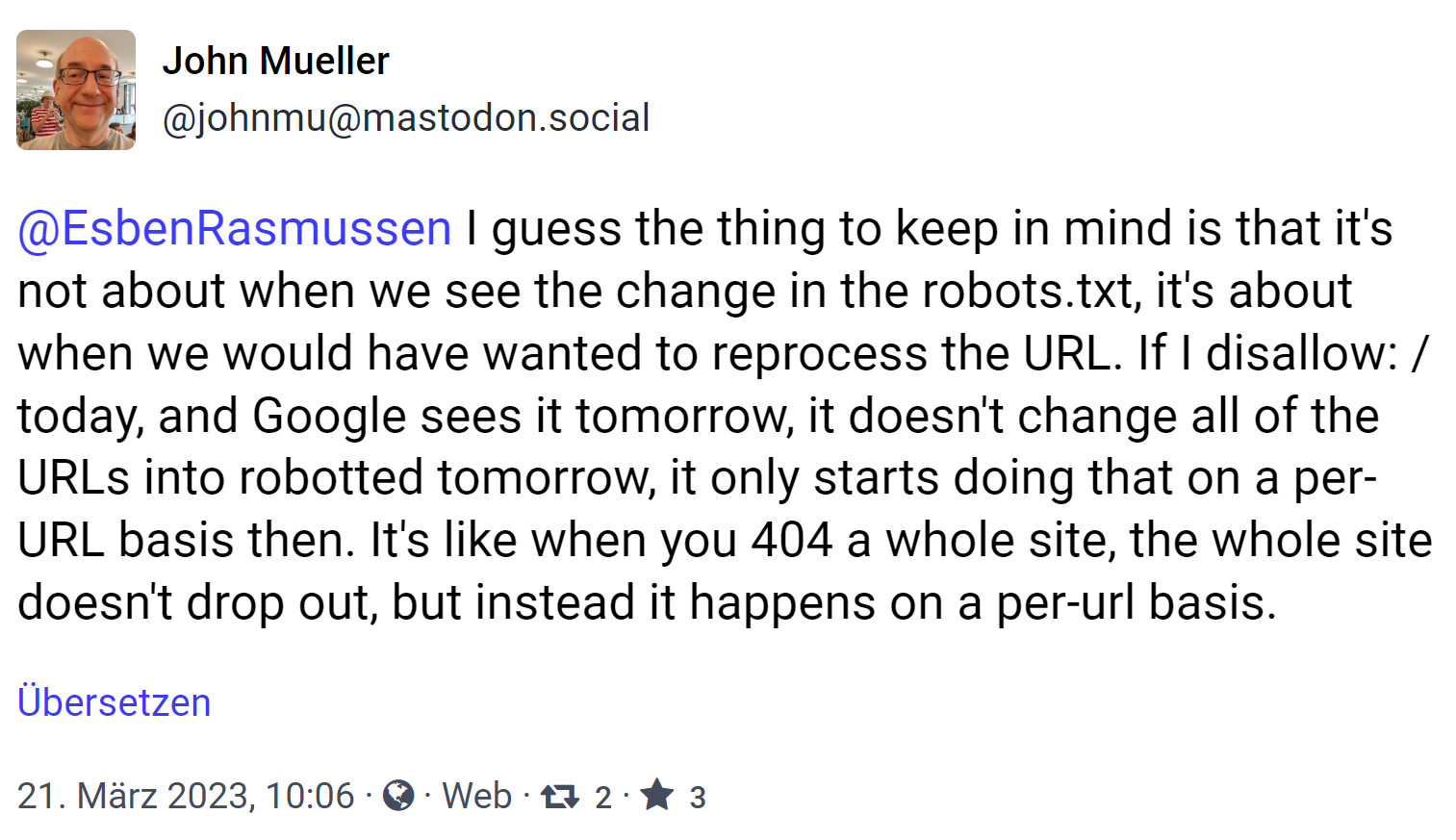
Allerdings ist es nicht so, dass sich eine solche Änderung der robots.txt sofort auf die gesamte Website auswirkt - selbst dann, wenn eine Direktive alle URLs betrifft. Wie jetzt John Müller von Google auf Mastodon erklärte, gehe es nicht darum, wann Google eine Direktive in der robots.txt sehe, sondern wann die betreffenden URLs von Google verarbeitet werden. Trifft Google auf ein disallow: /, dann werde sich das nicht morgen auf alle URLs auswirken, sondern es beginne, sich auf URL-Basis auszuwirken. Genauso verhalte es sich auch mit dem Status 404: Hier werde nicht gleich die komplette Website aus dem Index entfernt, sondern auch das geschehe auf URL-Basis.
I guess the thing to keep in mind is that it's not about when we see the change in the robots.txt, it's about when we would have wanted to reprocess the URL. If I disallow: / today, and Google sees it tomorrow, it doesn't change all of the URLs into robotted tomorrow, it only starts doing that on a per-URL basis then. It's like when you 404 a whole site, the whole site doesn't drop out, but instead it happens on a per-url basis.
Dabei werden die wichtigsten URLs einer Website zuerst betroffen sein, denn diese werden von Google am häufigsten gecrawlt. Das bedeutet, dass nach einer Änderung an der robots.txt, die alle URLs einer Website betrifft, vermutlich zuerst die Startseite sowie wichtige Kateorieseiten verarbeitet werden.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
