

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
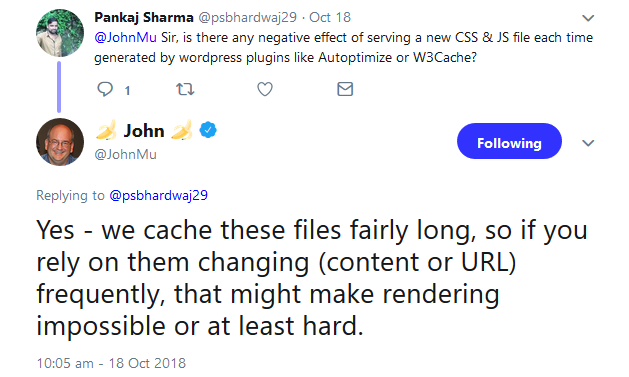
 Google behält JavaScript- und CSS-Dateien von gecrawlten Webseiten lange im Cache. Das kann zu Problemen mit der Indexierung führen, wenn diese Dateien für die Aktualisierung von Inhalten benötigt werden.
Google behält JavaScript- und CSS-Dateien von gecrawlten Webseiten lange im Cache. Das kann zu Problemen mit der Indexierung führen, wenn diese Dateien für die Aktualisierung von Inhalten benötigt werden.
JavaScript- und CSS-Dateien machen oftmals einen großen Teils des Datenvolumens einer Webseite aus. Entsprechend aufwändig ist es, diese Dateien abzurufen - auch für den Googlebot. Daher speichert Google diese Dateien im Cache und behält sie dort für längere Zeit.
Das kann problematisch für Webseiten sein, die zur Aktualisierung von Inhalten JavaScript einsetzen. Darauf wies Johannes Müller in einem aktuellen Tweet hin:
Insbesondere News-Seiten, bei denen es auf eine schnelle Indexierung ankommt, dürften Probleme bekommen, wenn sie auf JavaScript zur Darstellung und Aktualisierung der Inhalte setzen.
Schon vor einigen Wochen wies Google darauf hin, dass bei Webseiten, die auf JavaScript basieren, mehrere Tage zwischen dem Crawlen und dem Indexieren vergehen können.
Ob es im oben genannten Fall hilft, die Cache-Dauer für die JavaScript- und CSS-Dateien im HTTP-Header entsprechend kurz anzusetzen, ist unklar. Das würde voraussetzen, dass sich Google an diese Werte hält.
Alternativ kann Dynamic Rendering genutzt werden: Hier wird für den Googlebot und andere Crawler reines, vorgerendertes HTML ausgespielt, während die Browser JavaScript erhalten, das sie interpretieren müssen.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
