

Google behandelt Hashtags auf Webseiten wir normale Worte
Hashtags auf Webseiten haben für Google keine besondere Bedeutung, sondern werden wie normale Worte behandelt.
 Direktiven mit Hash-Zeichen in der robots.txt können unter Umständen dazu führen, dass Google eine komplette Website nicht mehr crawlt. Hash-URLs werden von Google ohnehin meist ignoriert.
Direktiven mit Hash-Zeichen in der robots.txt können unter Umständen dazu führen, dass Google eine komplette Website nicht mehr crawlt. Hash-URLs werden von Google ohnehin meist ignoriert.
Auf manchen Websites kommen URLs mit Hash-Zeichen zum Einsatz: zum Beispiel auf AJAX-Seiten oder als Anker, um bestimmte Seitenbereiche direkt anspringen zu können. Der Bereich hinter einem Hash-Zeichen, das sogenannte URL-Fragment, wird von Google in der Regel ignoriert - mit wenigen Ausnahmen.
Die Verwendung von Hashes in der robots.txt kann ganz andere Probleme mit sich bringen: Sie kann sogar dazu führen, dass eine komplette Website nicht mehr gecrawlt wird. So war es in einem aktuellen Fall, der gerade auf Twitter zu sehen war. Ein Webmaster hatte sich gewundert, dass Google einige Seiten nicht indexiert hatte, weil sie per robots.txt blockiert waren. Offenbar gab es in der robots.txt die Direktive Disallow: /#*, um alle URLs mit Hash-Fragmenten zu sperren.
Das Hash-Zeichen dient in der robots.txt jedoch zur Kennzeichnung von Kommentaren. Die Folge: die Direktive wurde interpretiert als Disallow: /, was bewirkt, dass alle Seiten gesperrt sind. Das erklärte Johannes Müller in seiner Antwort:
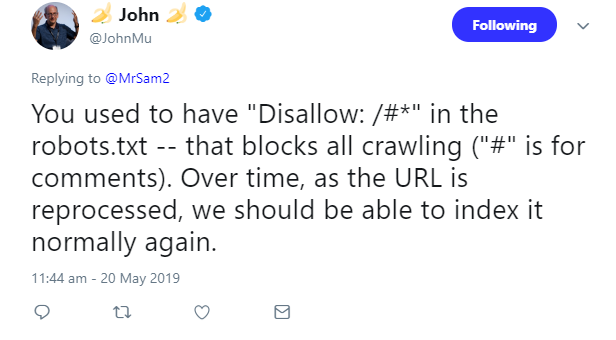
Müller erklärte, mit der Zeit würden die URLs erneut verarbeitet, und sie sollten dann wieder normal indexierbar sein.
Weil Google URL-Fragmente ohnehin nicht crawlt, ist es auch nicht notwendig, diese in der robots.txt anzugeben.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
