

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 WordPress erzeugt eine robots.txt, wenn die Datei nicht auf dem Server vorhanden ist. Kann das zu Problemen mit dem Crawlen durch Google führen?
WordPress erzeugt eine robots.txt, wenn die Datei nicht auf dem Server vorhanden ist. Kann das zu Problemen mit dem Crawlen durch Google führen?
In dieser Woche hatte Google erneut bekräftigt, dass dauerhafte Probleme beim Abruf der robots.txt-Datei einer Website zur Beeinträchtigung beim Crawlen der Website führen können. Lang andauernde Serverfehler können sogar zur Folge haben, dass Google eine Website aus dem Index entfernt. Der Grund dafür ist, dass Google vor dem Crawlen stets die robots.txt prüfen möchte. Laut Google kommt es aber bei rund 26 Prozent der Versuche zu Problemen beim Abruf der robots.txt.
Interessant ist dies im Zusammenhang mit einem der meist genutzten Content Management Systeme: WordPress. Dieses hat die Eigenschaft, eine robots.txt zu erzeugen, wenn sich diese Datei nicht auf dem Webserver befindet. Normalerweise wird eine robots.txt nämlich statisch in dem Verzeichnis auf dem Webserver abgelegt, in welchem sich die Dateien der betreffenden Website befinden.
Joost de Valk, der unter anderem das SEO-Plugin Yoast für WordPress ins Leben gerufen hat, fragte in diesem Zusammenhang Gary Illyes von Google, ob der Abruf der robots.txt bei Websites, die unter WordPress laufen, häufiger zu Problemen führe als bei anderen Websites.
Illyes antwortete, WordPress funktioniere gut, und es müsse schon zu einer groben Fehlkonfiguration kommen, damit es beim Aufruf einer robots.txt 5xx-Fehler gebe. Er wolle aber noch eine Analyse durchführen, um sicher zu sein:
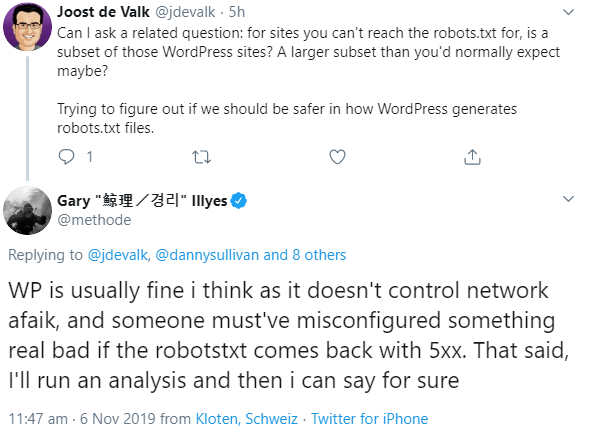
Joost de Valk erklärte in diesem Zusammenhang die Funktionsweise für die Erstellung der robots.txt durch WordPress und dass diese ab und zu Serverfehler bewirken könne. Sollte dies tatsächlich zu mehr Fehlern führen als im Durchschnitt, so müsse man WordPress so ändern, dass es eine statische robots.txt gebe:
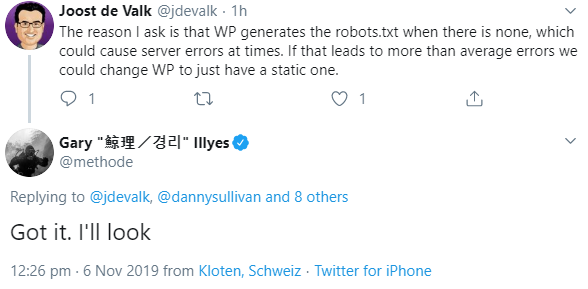
Wer bereits jetzt mögliche Probleme bei der Erstellung der robots.txt durch WordPress vermeiden möchte, sollte einfach eine statische robots.txt-Datei auf dem Webserver hinterlegen.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
