

Google erhöht wegen KI die Anforderungen an Inhalte für eine Indexierung
Google muss wegen der durch KI wachsenden Menge von Inhalten im Web mehr crawlen und setzt deshalb die Anforderungen für eine Indexierung herauf.
 Google indexiert manche Seiten, ohne dass sie in den Suchergebnissen auftauchen müssen. Der Unterschied zwischen technischer und praktischer Indexierung hat auch mit der robots.txt zu tun.
Google indexiert manche Seiten, ohne dass sie in den Suchergebnissen auftauchen müssen. Der Unterschied zwischen technischer und praktischer Indexierung hat auch mit der robots.txt zu tun.


Die robots.txt sollte nicht dazu verwendet werden, Seiten aus dem Google-Index zu entfernen oder eine Indexierung zu verhindern. Der Grund dafür ist, dass selbst bei Sperrung per "disallow" in der robots.txt betreffende URLs von Google indexiert werden können, und zwar dann, wenn es Links gibt, welche auf die betreffenden Seiten zeigen.
Und genau hier kommt der Unterschied zwischen technischer und praktischer Indexierung durch Google zum Tragen. Das bestätigte John Müller per Twitter:
"Yeah, the difference between technically indexed, and practically indexed is tricky."
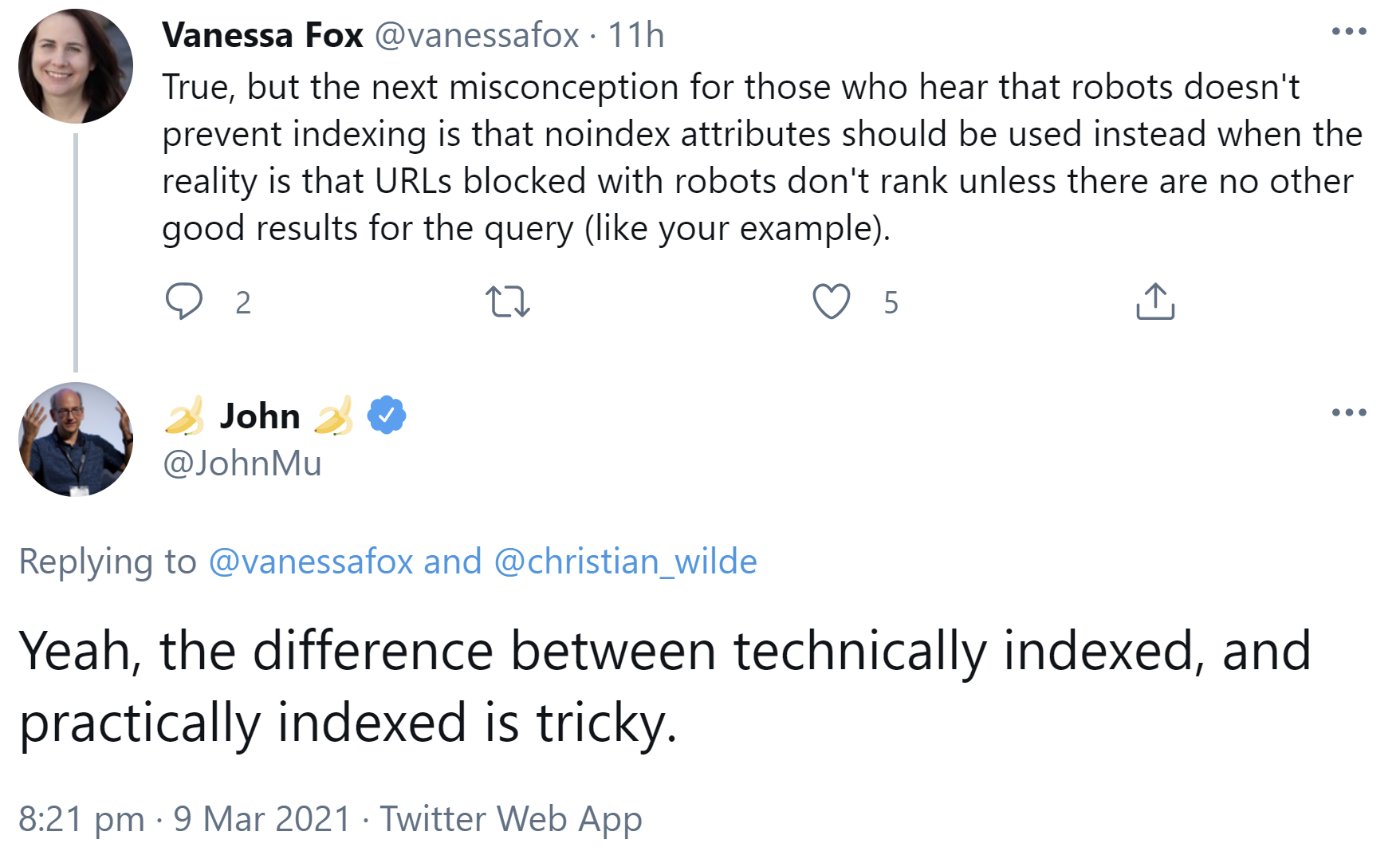
Der wesentliche Unterschied zwischen technischer und praktischer Indexierung bestehe im Grunde in der Frage, ob Ergebnisse in den Suchergebnissen erscheinen oder nicht. Dies komme zum Beispiel im Zusammenhang mit alten oder gelöschten Inhalten, Website-Umzügen, per robots.txt gesperrten URLs und ähnlichen Dingen zum Tragen. Technisch könne etwas indexiert sein, aber lohne es sich, etwas zu reparieren, das sowieso niemand sehen könne und das keine Probleme verursache?
"Indexed & practically seen in normal search results vs not seen. It comes up often with old / removed content, site-moves, robotted URLs, etc. Technically it might be indexed, but is it worth the time to fix something nobody sees & which doesn't cause issues?"
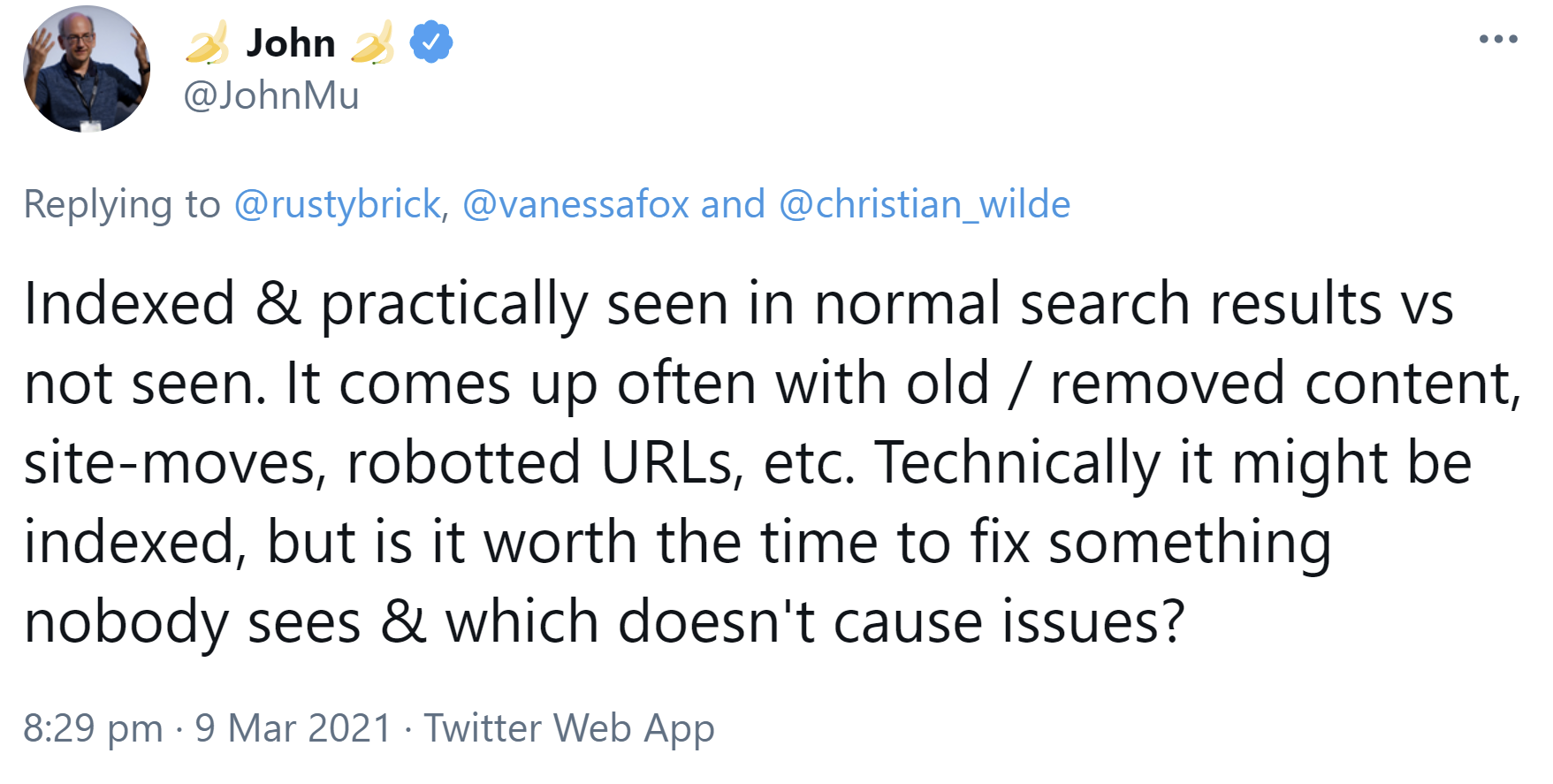
Fazit: Seiten, die Google technisch indexiert, aber die im Grunde nie in den Suchergebnissen erscheinen, sollten in der Regel kein Kopfzerbrechen bereiten. Möchte man Seiten auch technisch nicht indexiert wissen, sollte man "noindex" verwenden oder die Seiten löschen und einen 404- oder 410-Status senden. Ein Sperren per robots.txt genügt nicht.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
