

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 Eine nicht erreichbare robots.txt kann dazu führen, dass Google eine Website nicht crawlt, weil die Ressourcen als blockiert gelten.
Eine nicht erreichbare robots.txt kann dazu führen, dass Google eine Website nicht crawlt, weil die Ressourcen als blockiert gelten.

Für das Crawlen durch Google ist es wichtig, dass die robots.txt - sofern es eine solche Datei gibt - für Google erreichbar ist. Liefert der Aufruf der robots.txt dagegen eine Fehlermeldung, kann es passieren, dass Google das Crawlen als blockiert ansieht. Das erklärte John Müller gerade auf Twitter:
"If the robots.txt file is unreachable, we'll see that as blocking crawling."
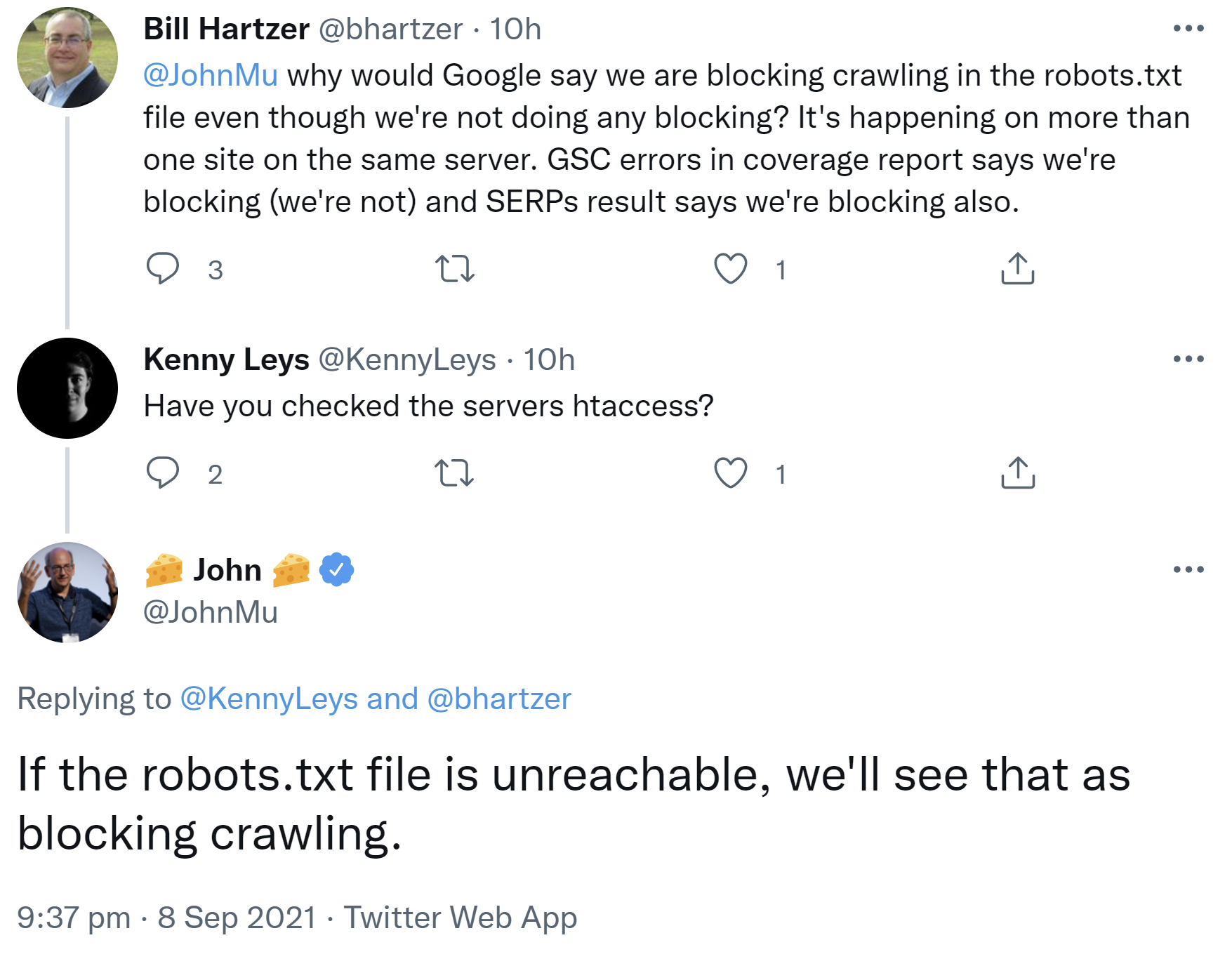
Kritisch sind dabei insbesondere 403- und 500er-Fehler. Erhält der Googlebot beim Versuch, die robots.txt abzurufen, einen solchen Status, dann wird die Website nicht gecrawlt.
Unproblematisch ist es dagegen, wenn es keine robots.txt gibt und beim Aufruf der Datei ein 404-Fehler zurückgegeben wird. In diesem Fall kann Google davon ausgehen, dass alle URLs der betreffenden Website gecrawlt werden dürfen.
Titelbild: Copyright Dirk Schumann - stock.adobe.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
