

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
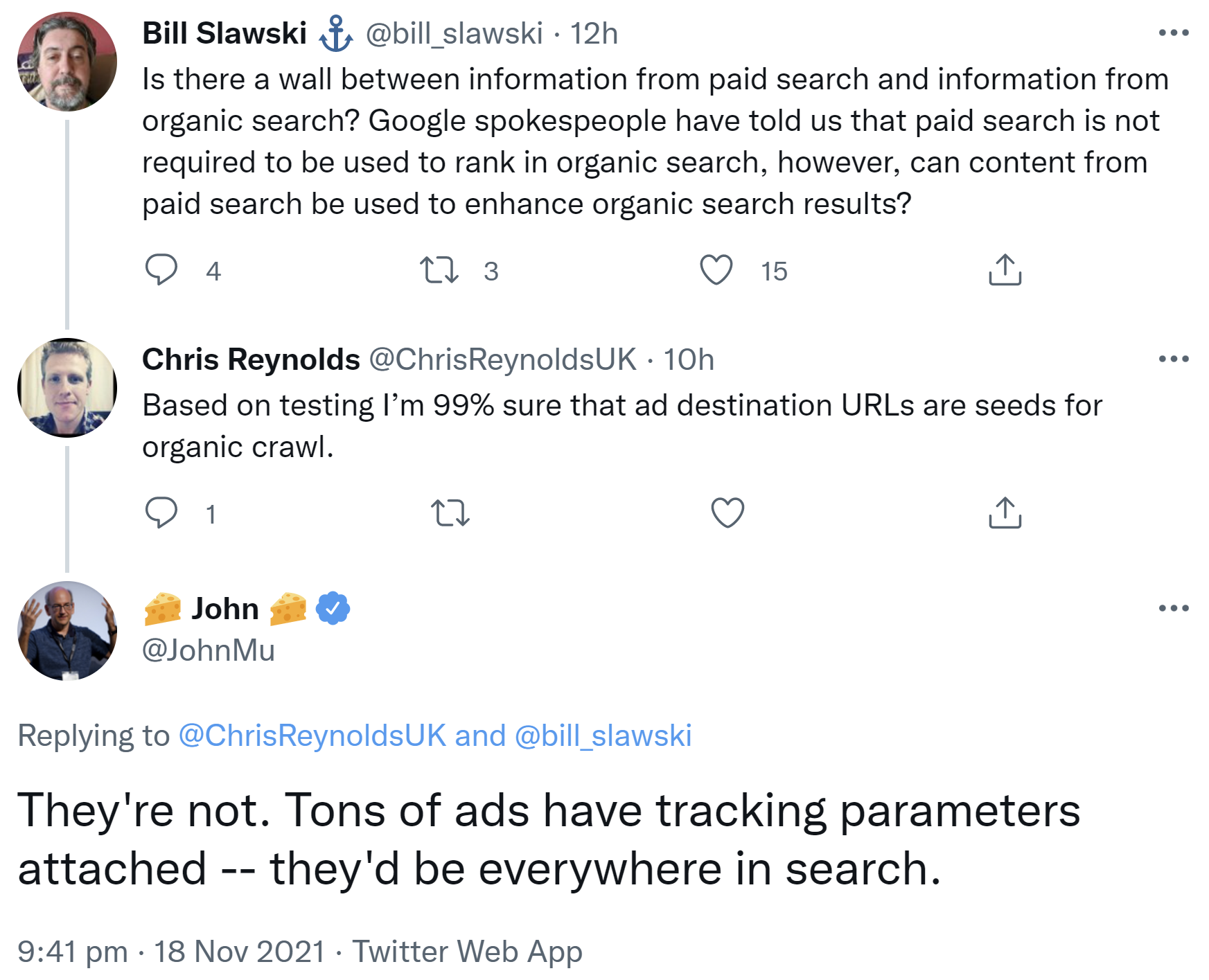
 Google unterscheidet beim Crawlen zwischen der organischen und der bezahlten Suche. Allerdings gibt es ein gemeinsames Crawl-Budget.
Google unterscheidet beim Crawlen zwischen der organischen und der bezahlten Suche. Allerdings gibt es ein gemeinsames Crawl-Budget.


Nicht nur für die organische Suche setzt Google Crawler ein, sondern auch im Bereich der bezahlten Suche, also für Google Ads. Gibt es dabei Gemeinsamkeiten bzw. Überschneidungen?
Auf die Frage, ob Google Ziel-URLs von Ads als Seeds, also als Ausgangspunkte zum Crawlen, verwende, antwortete John Müller, das sei nicht der Fall. Die Tracking-Parameter von Anzeigen wären ansonsten überall in der Suche zu finden:
"They're not. Tons of ads have tracking parameters attached -- they'd be everywhere in search."
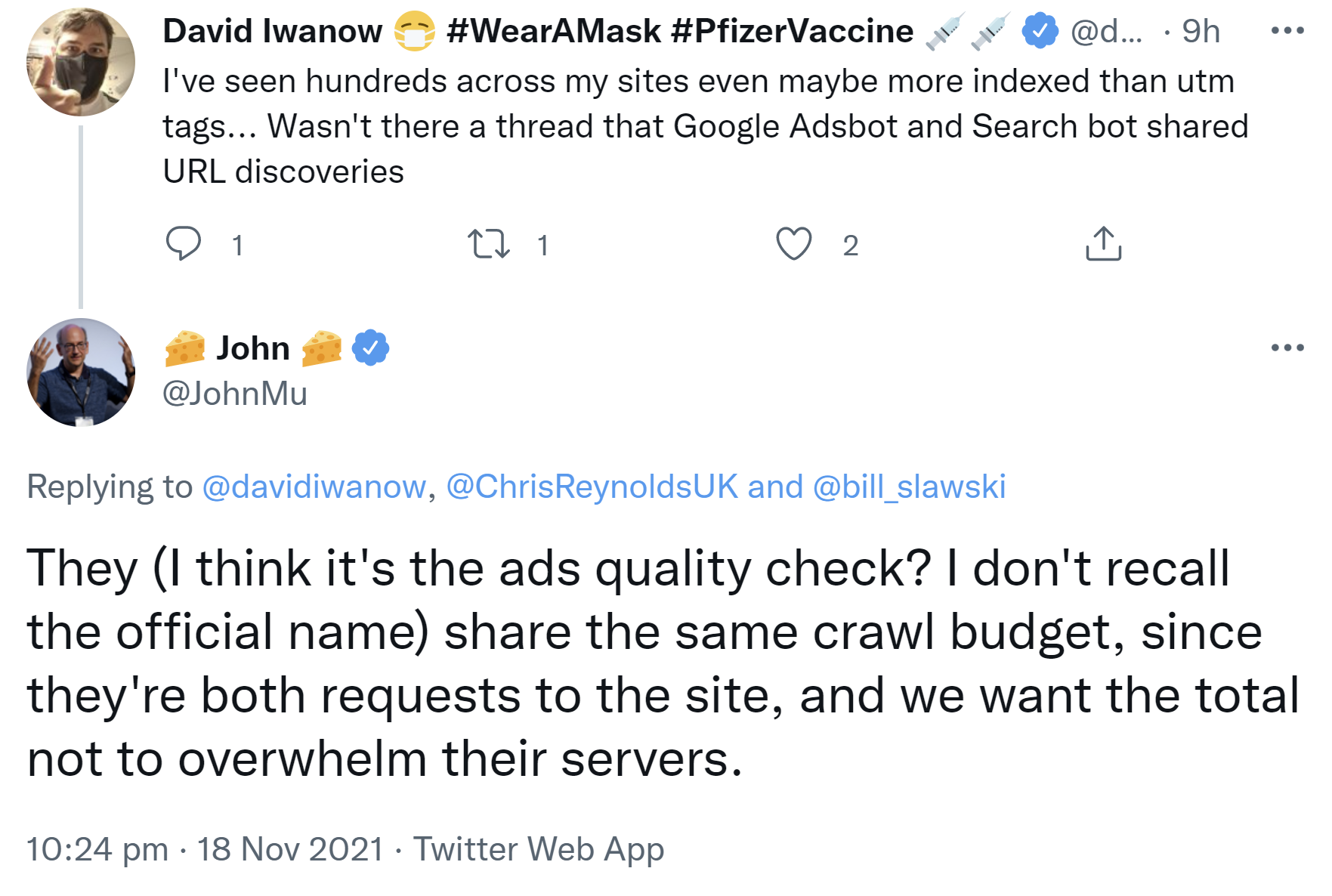
Allerdings gebe es ein gemeinsames Crawl-Budget. Der Grund sei, dass es sich jeweils um Requests zur selben Website handele und man die Server nicht überlasten wolle:
"They (I think it's the ads quality check? I don't recall the official name) share the same crawl budget, since they're both requests to the site, and we want the total not to overwhelm their servers."
Google sei wirklich sehr strikt bei der Trennung des Crawlens, so Müller weiter. Alles andere würde das Tracking deutlich erschweren. In der Vergangenheit habe es zwar Quereffekte durch öffentliche Logfiles gegeben, aber solche öffentlichen Logs seien heute sehr selten:
"are generally happy that we do so (it would make tracking success much harder). In the past, some sites had their logs public, which caused some cross-pollination, but public server logs are uncommon nowadays."
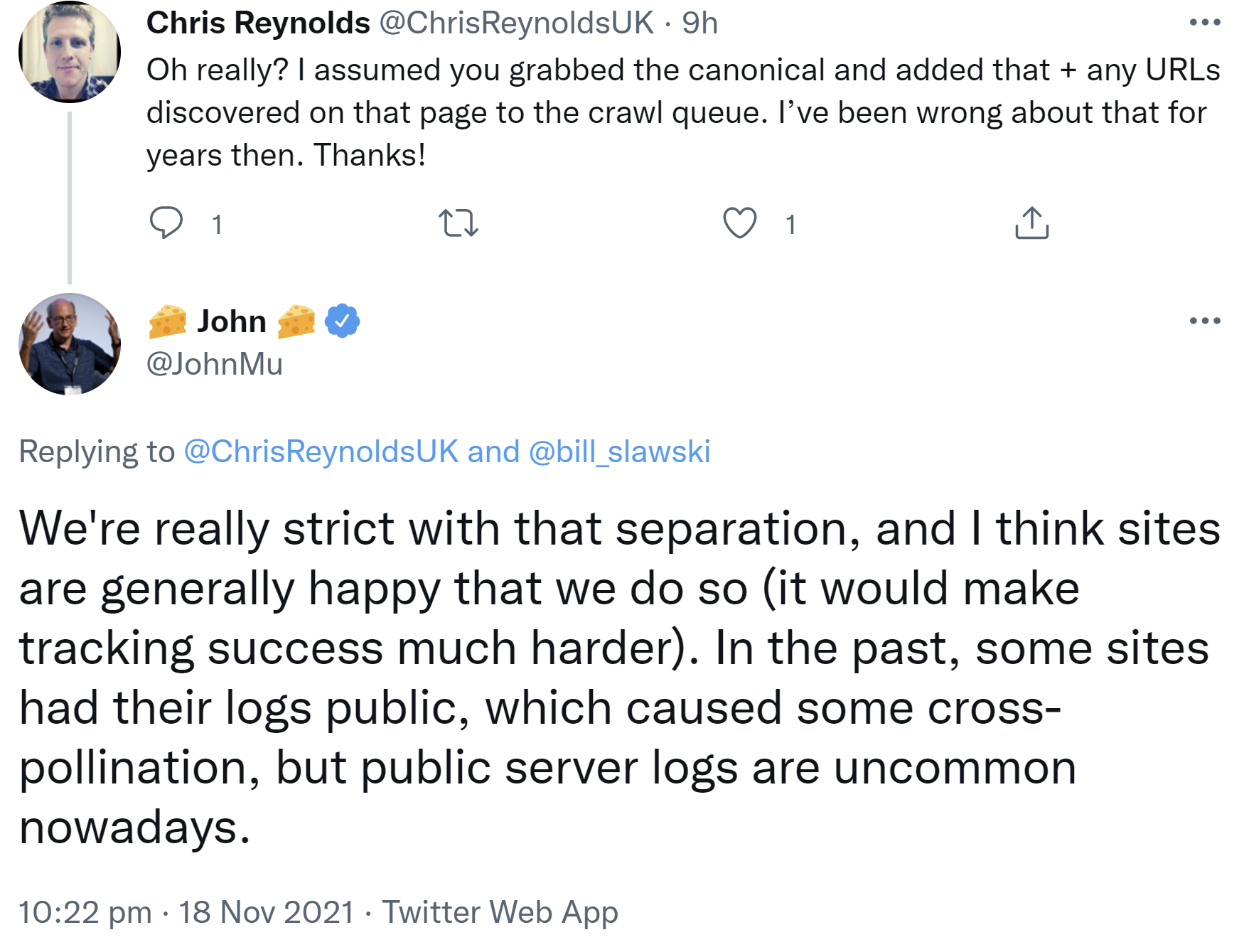
Inhaltlich gibt es also eine klare Trennung beim Crawlen zwischen organischer und bezahlter Suche. Lediglich das Crawl-Budget gilt für beide Bereiche gemeinsam.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
