 Wenn der Abruf der robots.txt einer Website einen undefinierten HTTP-Status als Antwort liefert, kann Google das Crawlen der kompletten Website einstellen.
Wenn der Abruf der robots.txt einer Website einen undefinierten HTTP-Status als Antwort liefert, kann Google das Crawlen der kompletten Website einstellen.
Google reagiert sehr sensibel auf Probleme beim Abruf der robots.txt. Erhält der Googlebot zum Beispiel einen Serverfehler (500er), wird das Crawlen sämtlicher URLs der betreffenden Website eingestellt.
Doch nicht nur Serverfehler sind beim Abruf der robots.txt problematisch. Auch wenn ein nicht definierter HTTP-Status zurückgeliefert wird, kann Google das Crawlen einer Website abbrechen. Das zeigt ein aktuelles Beispiel. Ein Nutzer hatte bemerkt, dass Google seit mehreren Tagen keine URLs seiner Website mehr abrief:
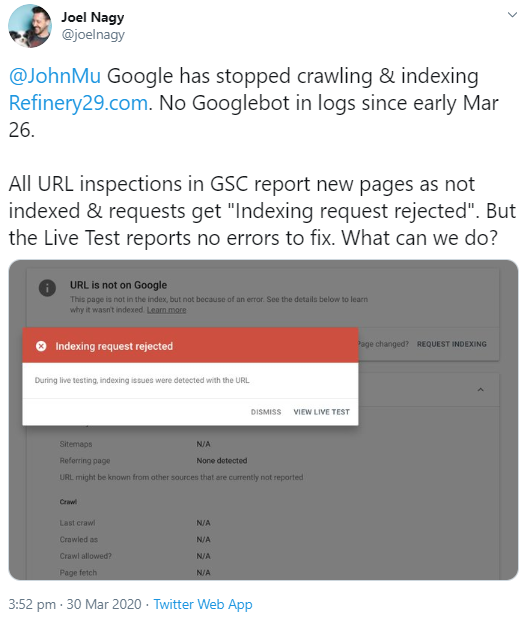
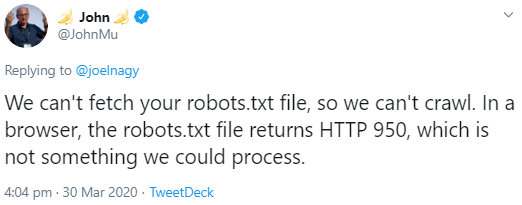
Der Grund dafür war offenbar, dass beim Abruf der robots.txt ein HTTP-Status 950 gesendet wurde. Dieser besagt, dass bei der Interpretation einer Administrator-Anfrage des Clients ein Fehler aufgetreten ist. Offiziell dokumentiert ist das allerdings nicht. Google kann diesen Status laut Johannes Müller nicht verarbeiten:
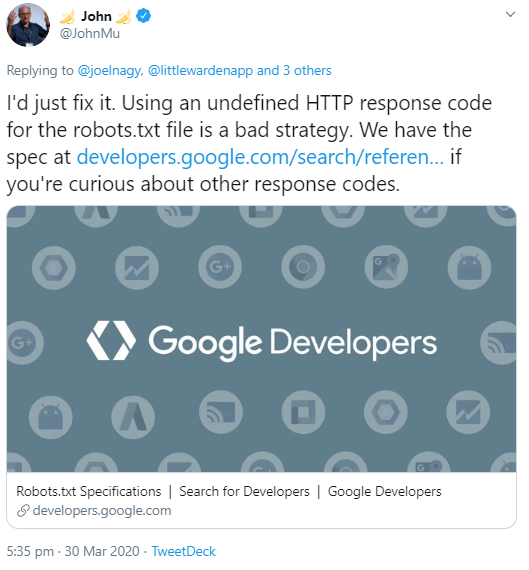
Müller empfahl, das Problem zu beheben und verwies dabei auf die entsprechende Hilfeseite zur Verwendung von robots.txt-Dateien.
Es ist übrigens kein Problem, wenn der Abruf der robots.txt einen 404-Status liefert. Wenn keine robots.txt gefunden wird, crawlt Google eine Website ganz normal.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige
















