 Wer Seiten per 404 oder 410 aus dem Google-Index entfernen möchte und die betreffenden URLs gleichzeitig per robots.txt sperrt, kann lange warten, denn Google kann den HTTP-Status von gesperrten URLs nicht erkennen.
Wer Seiten per 404 oder 410 aus dem Google-Index entfernen möchte und die betreffenden URLs gleichzeitig per robots.txt sperrt, kann lange warten, denn Google kann den HTTP-Status von gesperrten URLs nicht erkennen.
Eine Möglichkeit, URLs aus dem Google-Index zu entfernen, ist, bei deren Aufruf den HTTP-Status 404 oder 410 zu senden. Beim nächsten Crawlen durch den Googlebot werden die entsprechenden URLs dann gelöscht.
Einzelne Webmaster möchten aber anscheinend besonders sichergehen und sperren unerwünschte URLs zusätzlich per robots.txt. Das aber funktioniert nicht, denn in diesem Fall kann Google den HTTP-Status der betreffenden URLs nicht mehr auslesen.
Um einen solchen Fall ging es gerade auf Twitter. Ein Nutzer beschwerte sich darüber, dass für einige seiner URLs in der Google Search Console noch Warnungen angezeigt würden ("Indexiert, obwohl per robots.txt gesperrt"). Dabei würde für die betreffenden URLs bereits seit sechs Monaten der Status 410 gesendet.
Johannes Müller antwortete, wenn eine URL per robots.txt blockiert sei, könne Google den Statuscode nicht abrufen:
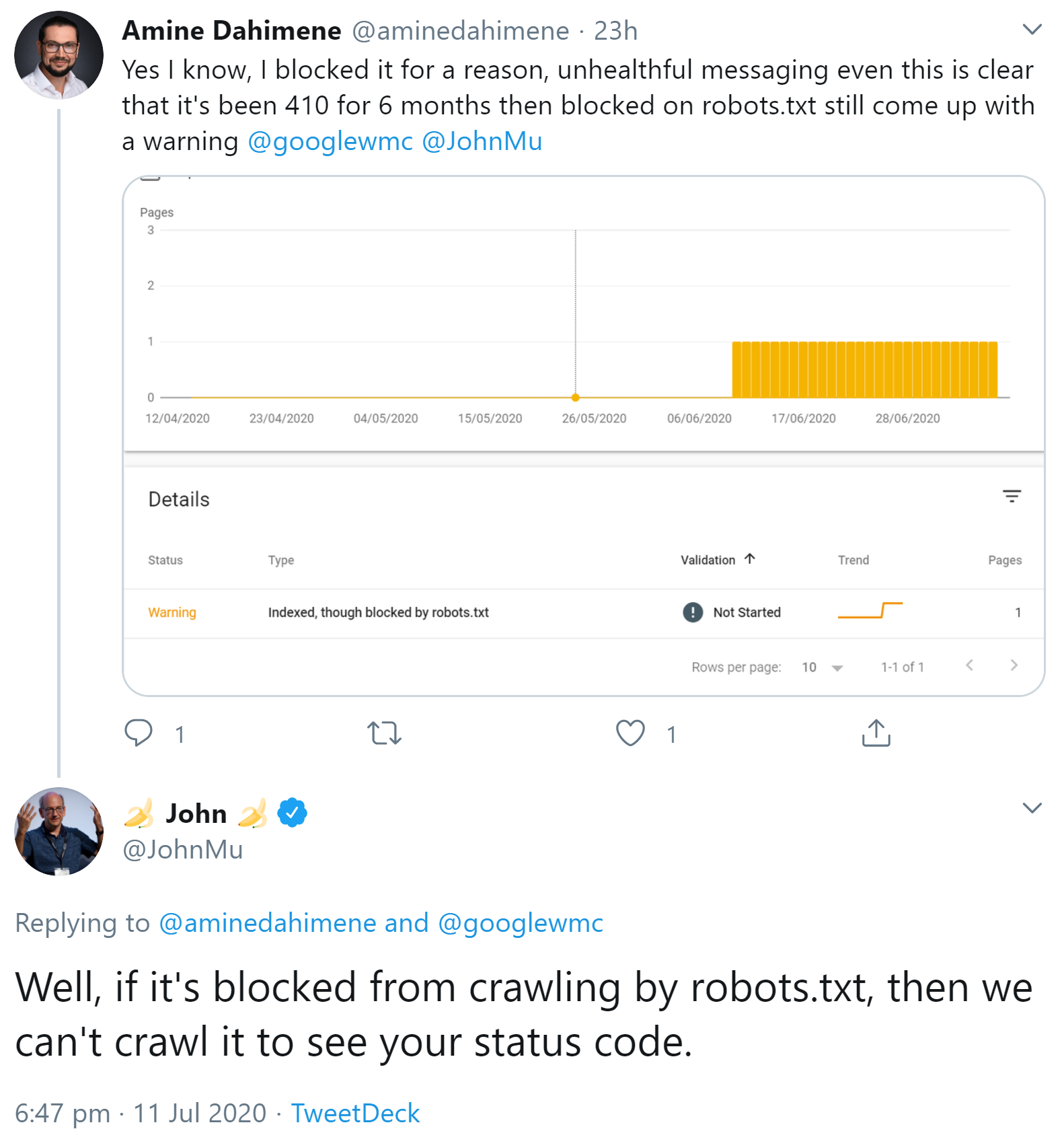
So ähnlich verhält es sich ürigens auch in einem anderen Fall: Wer Seiten mit dem Meta Robots Tag "noindex" aus dem Index entfernen möchte, darf die betreffenden URLs auch nicht per robots.txt sperren, denn das würde verhindern, dass der Googlebot die Seiten abrufen und die Tags auslesen kann.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com
SEO-Experte.
Sie benötigen Beratung für Ihre Webseite? Klicken Sie hier
Anzeige















