

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.
 Google ruft die robots.txt nicht bei jedem Crawl ab, sondern nutzt auch eine im Cache abgelegte Version der Datei. Das passiert etwa einmal pro Tag.
Google ruft die robots.txt nicht bei jedem Crawl ab, sondern nutzt auch eine im Cache abgelegte Version der Datei. Das passiert etwa einmal pro Tag.


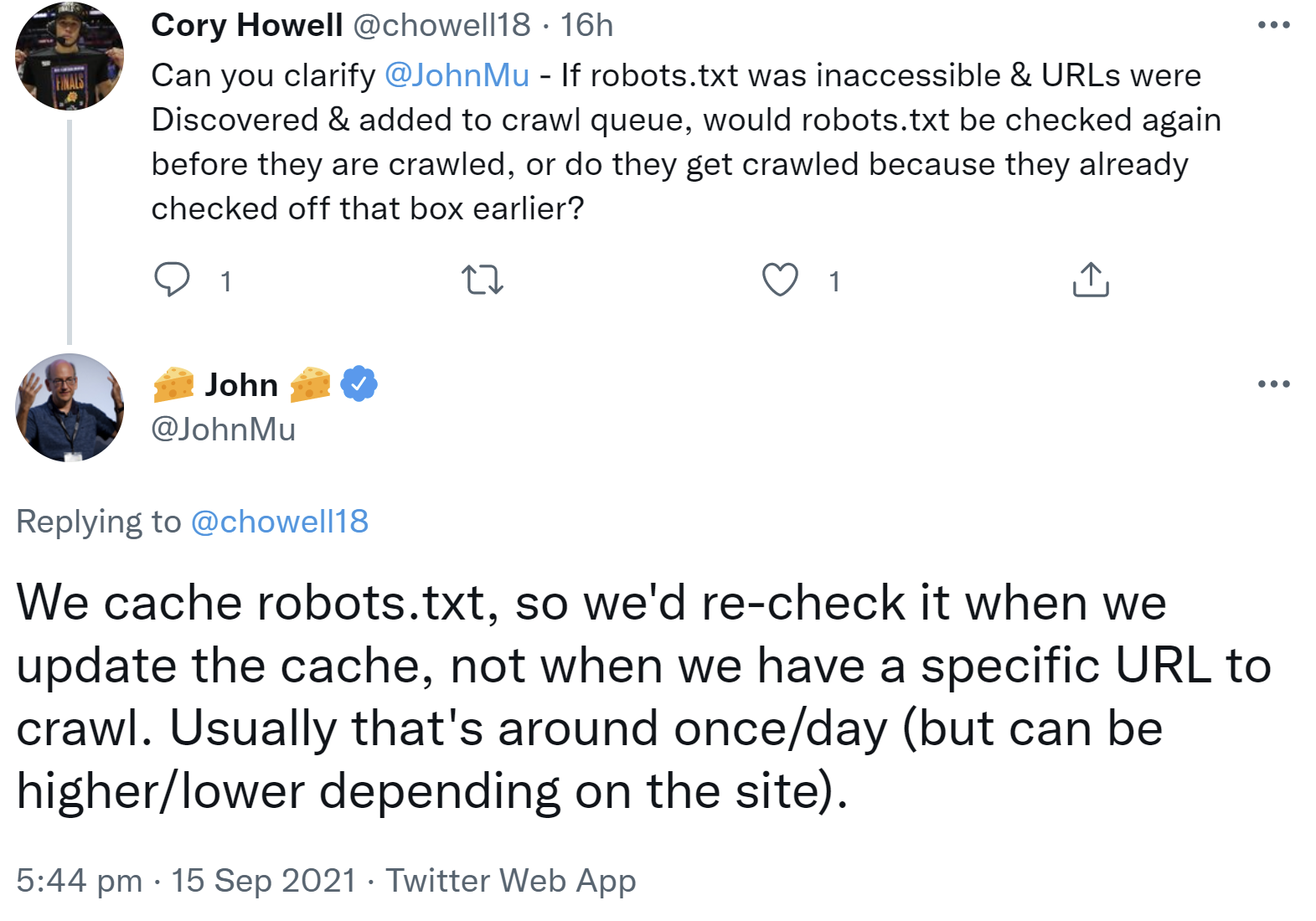
Google crawlt nur solche URLs, auf die der Zugriff per robots.txt nicht gesperrt ist. Um das zu prüfen, muss Google die robots.txt abrufen. Das passiert aber nicht vor jedem Crawl von URLs. Google legt die robots.txt nämlich in seinem Cache ab und aktualisiert sie immer wieder - etwa einmal pro Tag, manchmal auch häufiger oder auch seltener. Die robots.txt wird also dann abgerufen, wenn die Version im Cache aktualisiert wird und nicht, wenn eine bestimmte URL gecrawlt werden soll. Das erklärte John Müller auf Twitter:
"We cache robots.txt, so we'd re-check it when we update the cache, not when we have a specific URL to crawl. Usually that's around once/day (but can be higher/lower depending on the site)."
Zuletzt hatte Google wieder darauf hingewiesen, dass die Nicht-Verfügbarkeit der robots.txt dazu führen kann, dass Google eine Website nicht crawlt. Das kann dann passieren, wenn beim Abruf der robots.txt ein Fehler wie ein 403 oder ein 500er geworfen wird.
Titelbild: Copyright Patrick Daxenbichler - Fotolia.com



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
