

Wenn Google rel Canonical ignoriert: weiterer Hinweis, dass ChatGPT Google nutzt
Google beachtet rel=canonical Attribut nicht immer. Das kann zu Problemen führen und wirkt sich auch auf ChatGPT und andere KI-Suchen aus.
 Um die Anzeige bevorzugter URLs in den Suchergebnissen von Google zu forcieren, kann man notfalls auch die nicht gewünschten URLs per robots.txt sperren - auch dann, wenn diese bereits indexiert sind.
Um die Anzeige bevorzugter URLs in den Suchergebnissen von Google zu forcieren, kann man notfalls auch die nicht gewünschten URLs per robots.txt sperren - auch dann, wenn diese bereits indexiert sind.

Wenn es die gleichen Inhalte auf einer Website unter verschiedenen URLs gibt, ist es wichtig, Google klare Signale darüber zu senden, welche URL in den Suchergebnissen erscheinen soll. Zur Festlegung der Canonical URL verwendet Google verschiedene Signale wie zum Beispiel interne Links, Weiterleitungen oder auch Canonical-Links.
Eine weitere Möglichkeit, bestimmte URLs in der Suche gegenüber anderen URLs zu bevorzugen, ist, die ungewünschten URLs per robots.txt zu sperren. Das funktioniert sogar dann, wenn die betreffenden URLs bereits indexiert sind.
Interessant kann diese Variante zum Beispiel dann sein, wenn es auf einer Website bestimmte Inhalte sowohl als HTML-Seite als auch als PDF-Datei gibt und man die PDF-Datei nicht in den Suchergebnissen sehen möchte.
John Müller wies per Twitter auf diese Möglichkeit hin. Wenn es andere crawlbare Inhalte auf einer Website gebe, die anstelle der per robots.txt gesperrten URL ranken könnten, dann sei es sehr selten, dass Google die gesperrte URL anzeige:
"Sure, robots.txt is fine there. Especially when you have other crawlable content on the site that could rank instead, it would be pretty rare that we'd show a robotted URL. (You might see it with site:-queries though)"
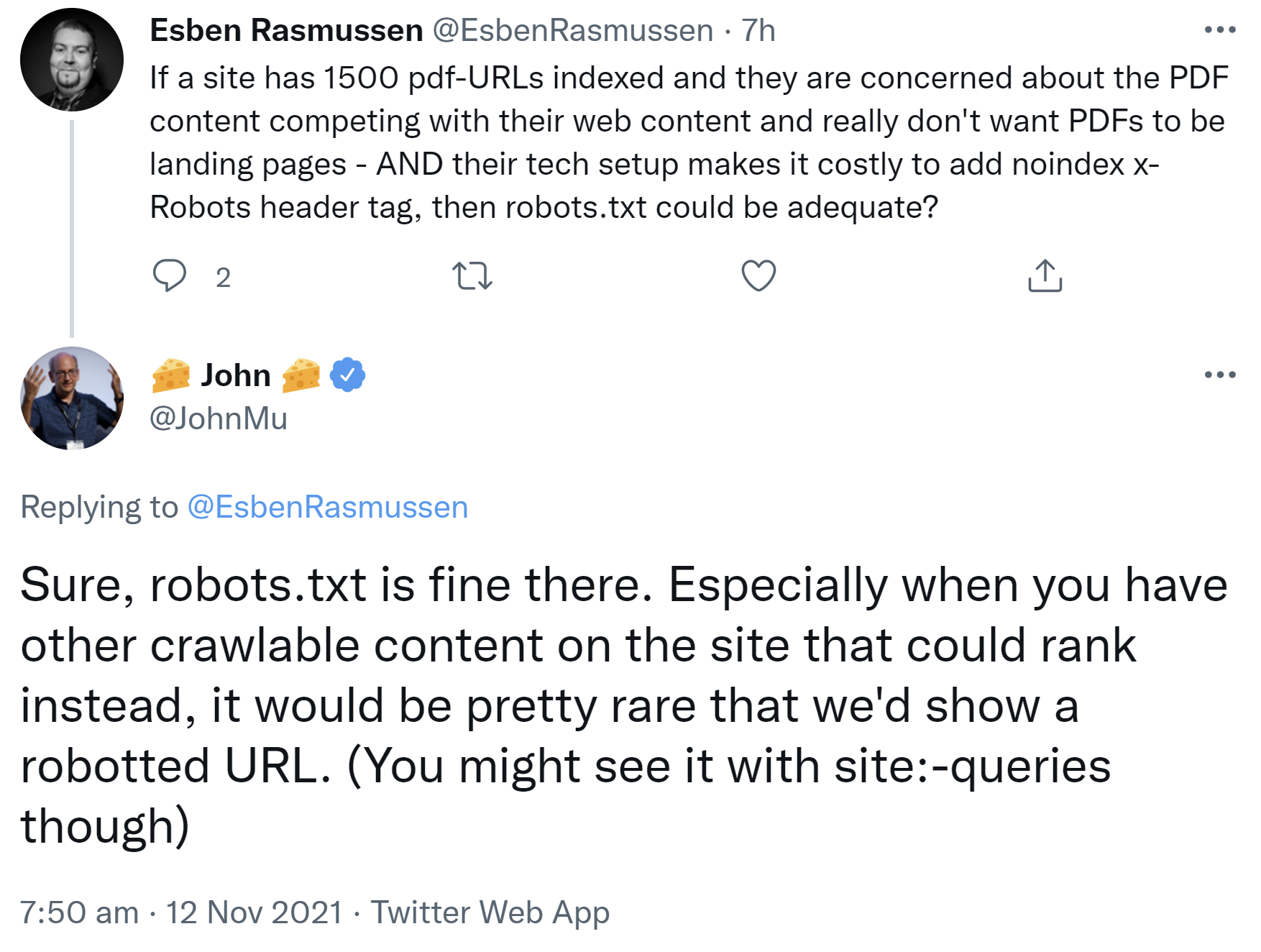
Diese Option kann zum Beispiel dann sinnvoll sein, wenn ein "noindex" oder das Setzen eines Canonical-Links im HTTP-Header von PDF-Dateien aus technischen Gründen nicht oder nur schwierig umzusetzen ist.
Titelbild: Copyright fotomek - Fotolia.com




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
