

Crawlen: Google erklärt das 2-MB-Limit und das 15-MB-Limit
Google erklärt die verschiedenen Limits beim Crawlen und warum Webseiten immer größer werden.

Das Verwenden von 'Crawl-delay' in der robots.txt kann in bestimmten Fällen dazu führen, dass Google die komplette Website nicht mehr crawlen kann.


Google berücksichtigt die Anweisung "Crawl-delay" in der robots.txt nicht. John Müller erklärte in einer früheren Ausgabe von "SEO Snippets", die Angabe bestimmter Zeitintervalle zwischen Requests ergebe keinen Sinn. Webserver können heute viele Requests pro Sekunde bearbeiten. Zudem seien Webserver sehr dynamisch, so dass ein bestimmter Wert ebenfalls nicht sinnvoll sei.
Das Nicht-Berücksichtigen von "Crawl-delay" durch Google kann in ungünstigen Fällen dazu führen, dass Google eine komplette Website nicht mehr crawlen kann. Dazu muss in der robots.txt eine bestimmte Reihenfolge der Direktiven und der User Agents angegeben sein. Ein Beispiel dafür teilte ein Nutzer auf Twitter. Er schrieb, dass eine alte Website plötzlich komplett für die Suche blockiert war.
In der betreffenden robots.txt ist zunächst die für alle User-Agents gültige Anweisung "Crawl-delay: 2" zu finden. Darunter folgt eine Direktive, die nur für den Mozbot gilt, für den die gesamte Website blockiert ist.
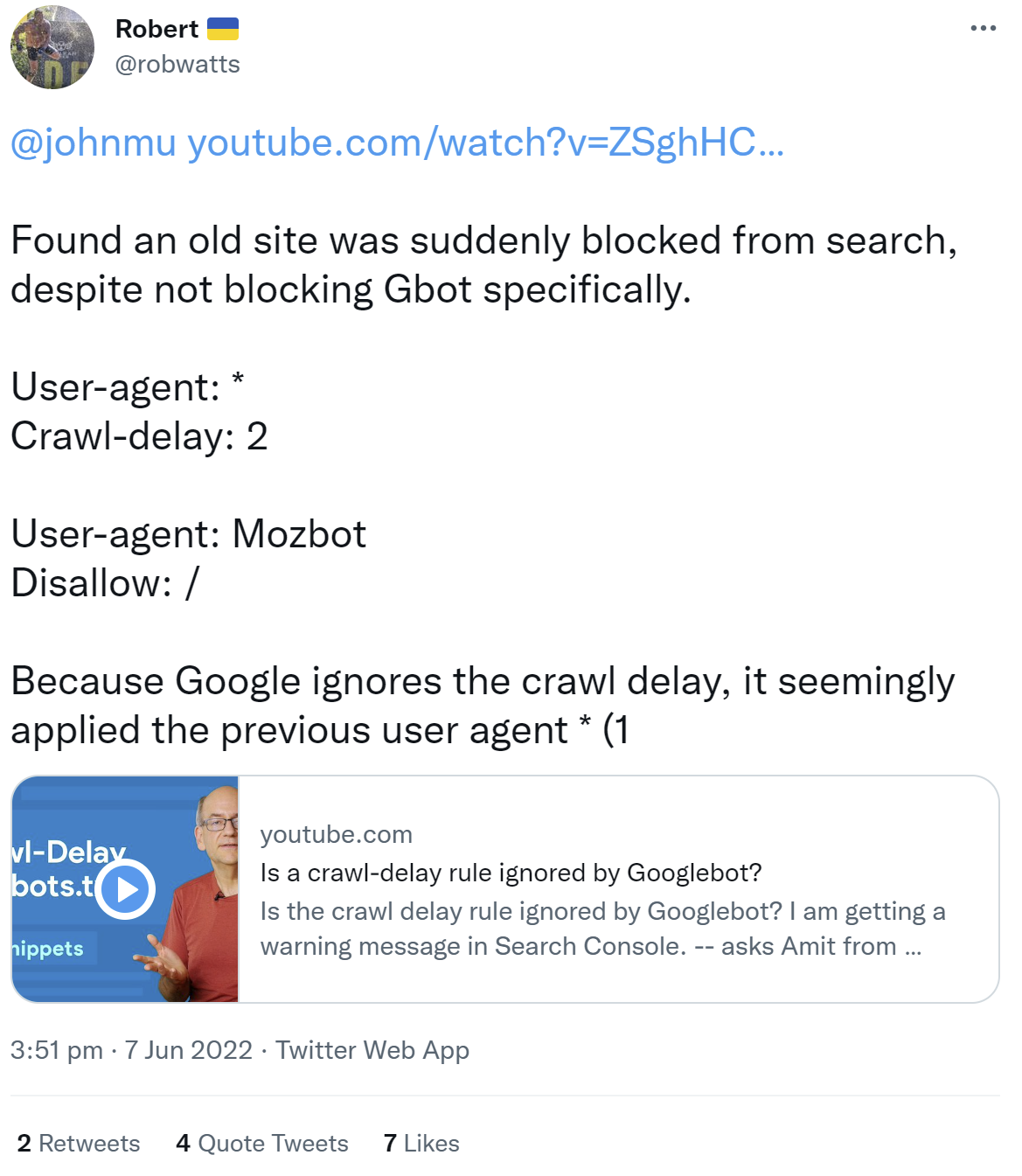
Weil nun Google das "Crawl-delay" ignoriert, wendet es das "*", das alle User Agents anspricht, auf das "Disallow: /" an, was bedeutet, dass das Crawlen der Website für alle User Agents verboten ist. Offenbar ignoriert Google die Nennung des Mozbots komplett.
Sicherlich ist das ein Spezialfall, aber es zeigt, dass manchmal gravierende Probleme mit der robots.txt bestehen können, die nicht auf den ersten Blick sichtbar sind.
Danke für dieses Fundstück an Glenn Gabe.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
