

Google: Robots.txt sollte nicht dynamisch geändert werden
Es ist keine gute Idee, die robots.txt einer Website dynamisch zu ändern, um zum Beispiel die Serverlast durch das Crawlen zu steuern.
 In vielen Fällen ist es egal, ob URLs per robots.txt oder per 'noindex' gesperrt werden, obwohl es eigentlich einen grundlegenden Unterschied gibt.
In vielen Fällen ist es egal, ob URLs per robots.txt oder per 'noindex' gesperrt werden, obwohl es eigentlich einen grundlegenden Unterschied gibt.


Es gibt verschiedene Möglichkeiten, URLs aus den Ergebnissen von Suchmaschinen auszuschließen. Eine Möglichkeit ist das Sperren per robots.txt. Google und andere Suchmaschinen crawlen per robots.txt gesperrte URLs nicht. Doch auch per robots.txt gesperrte URLs können theoretisch in den Suchergebnissen erscheinen - zum Beispiel dann, wenn sie vor dem Sperren schon indexiert waren. Allerdings zeigt Google dann keine Inhalte der gesperrten Seiten in den Suchergebnissen an.
Das Setzen von "noindex" ist eine weitere Möglichkeit, Seiten aus der Suche auszuschließen. Durch diese Direktive, die entweder per Meta-Robots-Tag oder per HTTP-Header (X-Robots) gesetzt werden kann, werden die Suchmaschinen angewiesen, die betreffende Seite nicht zu indexieren.
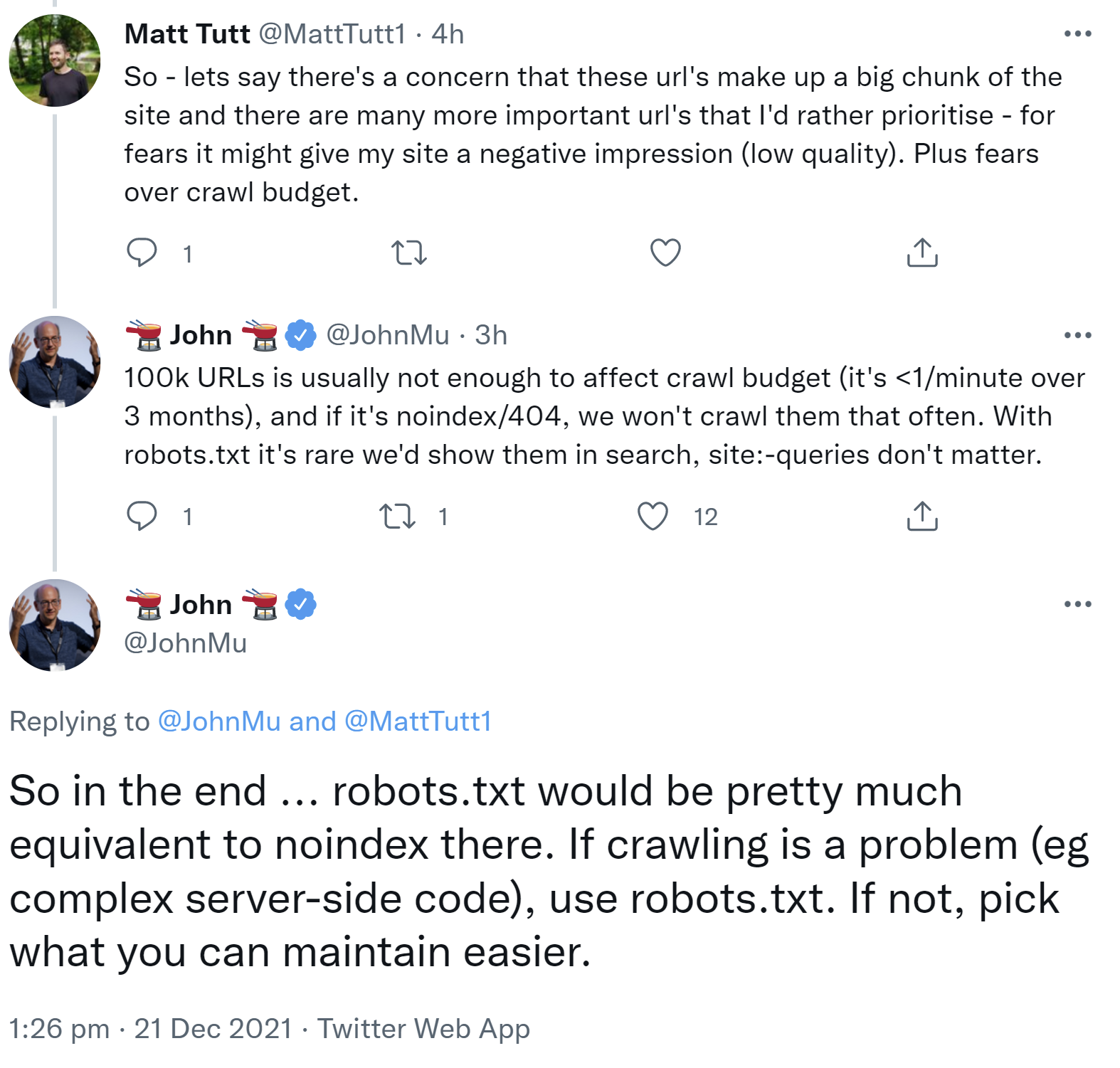
Für Google sind beide Möglichkeiten gleichwertig - zumindest in vielen Fällen. Das zeigt ein aktuelles Beispiel auf Twitter. Ein Nutzer hatte John Müller gefragt, ob er rund 100.000 URLs seiner Website, die er aus der Suche entfernen möchte, zunächst per "noindex" und danach per robots.txt sperren solle. Daei ging es ihm neben einer Bereinigung der Suchergebnisse auch um das Einsparen von Crawl-Budget.
John Müller antwortete, 100.000 URLs seien nicht genug, um das Crawl-Budget zu beeinflussen. Und bei einem "noindex" oder einem 404-Status würde Google die URLs sowieso seltener crawlen. Wenn URLs per robots.txt gesperrt seien, würde Google sie nur selten in den Suchergebnissen anzeigen, wobei Site-Suchanfragen nicht ins Gewicht fallen:
"100k URLs is usually not enough to affect crawl budget (it's <1/minute over 3 months), and if it's noindex/404, we won't crawl them that often. With robots.txt it's rare we'd show them in search, site:-queries don't matter."
Letztendlich sei in diesem Fall ein Sperren per robots.txt gleichwertig zu "noindex". Wenn das Crawlen ein Problem sei, dann solle man die robots.txt verwenden. Wenn nicht, sei das zu verwenden, was einfacher sei:
"So in the end ... robots.txt would be pretty much equivalent to noindex there. If crawling is a problem (eg complex server-side code), use robots.txt. If not, pick what you can maintain easier."
Sowohl robots.txt als auch noindex ist also in den meisten Fällen geeignet, unerwünschte URLs aus den Suchergebnissen zu entfernen. Der sauberste Weg ist aber, die URLs zunächst per 'noindex' aus dem Index zu entfernen und sie anschließend per robots.txt zu sperren.



Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
