

Google: Bei technischen Crawling-Problemen kann Aufteilen auf Domains und Subdomains helfen
Wenn Google aus technischen Gründen beim Crawlen an Grenzen stößt, kann das Aufteilen der Ressourcen auf mehrere Domains oder Subdomains helfen.
Wenn Google auf URLs stößt und diese nicht crawlt, dann liegt es nicht an der URL und den mit ihr verbundenen Inhalten, sondern an der Website. Und das hat einen ganz einfachen Grund.


Dass Google nicht alle URLs einer Website indexiert, ist normal. Dass Google bestimmte URLs einer Website nicht einmal crawlt, kann auch vorkommen. Angenommen, das passiert, obwohl die URL nicht per robots.txt gesperrt ist und sie grundsätzlich auch indexierbar wäre, dann taucht die URL im Bericht zur Indexabdeckung der Google Search Console unter "gefunden - zurzeit nicht indexiert" auf.
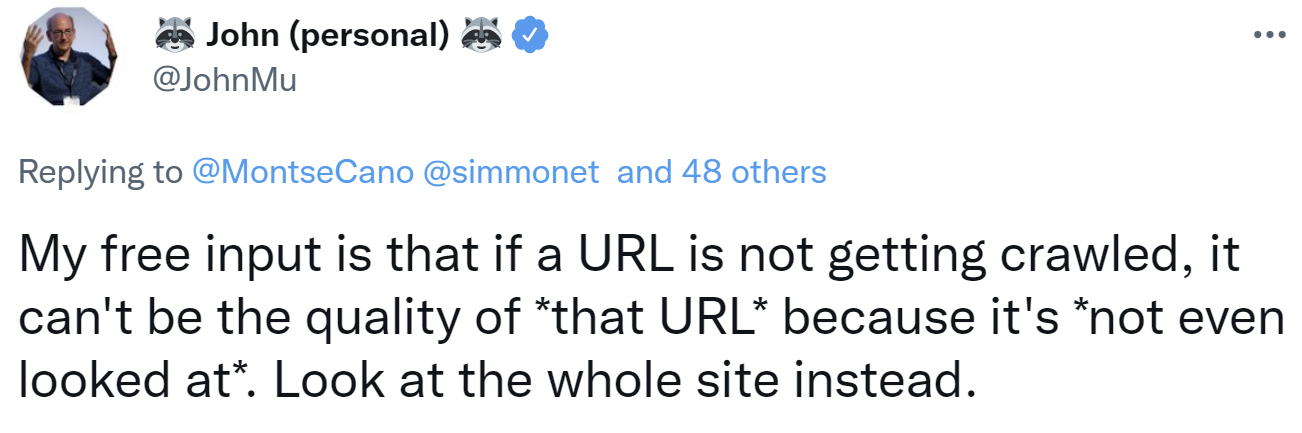
Wenn Google eine URL nicht crawlt, dann liegt das allerdings nicht an der URL selbst. Warum das so ist, hat John Müller per Twitter erklärt. Google kann nämlich die Qualität der URL gar nicht bewerten, ohne sie zuvor gecrawlt zu haben. Man solle sich in solchen Fällen besser die gesamte Website ansehen:
My free input is that if a URL is not getting crawled, it can't be the quality of *that URL* because it's *not even looked at*. Look at the whole site instead.
Etwas anders sieht es mit URLs aus, die Google crawlt und dann trotzdem nicht indexiert. Diese URLs sind im Bericht zur Indexabdeckung der Google Search Console unter "Gecrawlt - zurzeit nicht indexiert" zu finden. Hier sollte neben der Website auch die Qualität der Inhalte auf der jeweiligen Seite geprüft werden.




Premium-Partner (Anzeige)

Anzeigen








![]()

![]()
![]()
![]()
